1105_01_Dataset_Down_F


Step 0: 在 Google Drive 建立一個資料夾
/Semicon_Analysis/Step 1: Mount Google Drive in Colab
from google.colab import drive
drive.mount('/content/drive')
#Check Drive Access
!ls /content/drive/My\ Drive/Semicon_Analysis/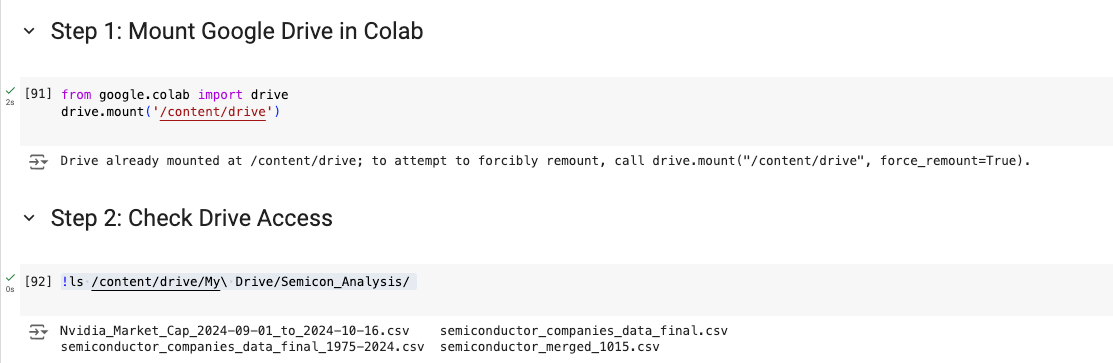
Step2 : Coding
import yfinance as yf
import pandas as pd
import os
from datetime import datetime
# Mount Google Drive in Colab (if running in Colab)
from google.colab import drive
drive.mount('/content/drive')
# Define file path to save the data in your Google Drive (adjust path as needed)
data_path = '/content/drive/My Drive/Semicon_Analysis/'
if not os.path.exists(data_path):
os.makedirs(data_path)
# Define company tickers
tickers = {
'Nvidia': 'NVDA',
'TSMC': '2330.TW', # Taiwan Stock Exchange
'Broadcom': 'AVGO',
'ASML': 'ASML',
'Samsung': '005930.KS', # Korea Stock Exchange
'AMD': 'AMD',
'Qualcomm': 'QCOM',
'Texas Instruments': 'TXN',
'Applied Materials': 'AMAT',
'Arm Holdings': 'ARM', # IPO in 2023
'Micron Technology': 'MU',
'Analog Devices': 'ADI',
'Lam Research': 'LRCX',
'KLA': 'KLAC',
'Intel': 'INTC',
'SK Hynix': '000660.KS', # Korea Stock Exchange
'Tokyo Electron': '8035.T', # Tokyo Stock Exchange
'Synopsys': 'SNPS',
'Marvell Technology': 'MRVL',
'MediaTek': '2454.TW' # Taiwan Stock Exchange
}
# Predefined data for specific companies
predefined_data = {
'Nvidia': {
'Funding Year': 1993,
'Employees': 29600,
'Major Products': 'GPU, AI Accelerators, Gaming Graphics Cards',
'Applications': 'AI, Gaming, Data Center, Autonomous Vehicles',
'Major Customers': 'Tesla, Google, Microsoft, AWS'
},
'TSMC': {
'Funding Year': 1987,
'Employees': 65152,
'Major Products': 'Semiconductor Manufacturing, Foundry Services',
'Applications': 'Mobile, Consumer Electronics, Automotive, High-Performance Computing',
'Major Customers': 'Apple, AMD, Qualcomm, Nvidia'
},
'Broadcom': {
'Funding Year': 1991,
'Employees': 20000,
'Major Products': 'Network Chips, Wi-Fi Chips, Storage Controllers',
'Applications': 'Networking, Wireless Communication, Data Storage',
'Major Customers': 'Apple, Cisco, Google, Facebook'
},
'ASML': {
'Funding Year': 1984,
'Employees': 41505,
'Major Products': 'Lithography Systems',
'Applications': 'Semiconductor Manufacturing',
'Major Customers': 'Intel, TSMC, Samsung'
},
'Samsung': {
'Funding Year': 1969,
'Employees': 127172,
'Major Products': 'Memory Chips, Displays, Smartphones',
'Applications': 'Mobile, Consumer Electronics, Data Center, Automotive',
'Major Customers': 'Apple, Qualcomm, Nvidia, Google'
},
'AMD': {
'Funding Year': 1969,
'Employees': 26000,
'Major Products': 'CPUs, GPUs, APUs',
'Applications': 'Gaming, Data Center, PCs, Servers',
'Major Customers': 'Microsoft, Sony, HP, Dell'
},
'Qualcomm': {
'Funding Year': 1985,
'Employees': 50000,
'Major Products': 'Mobile Processors, Modems, RF Front-End',
'Applications': 'Mobile, Automotive, IoT, 5G Networks',
'Major Customers': 'Apple, Samsung, Xiaomi, Vivo'
},
'Intel': {
'Funding Year': 1968,
'Employees': 124800,
'Major Products': 'Core Processors, Xeon Processors',
'Applications': 'PCs, Servers, Data Centers, AI',
'Major Customers': 'Dell, HP, Lenovo, Amazon'
},
'MediaTek': {
'Funding Year': 1997,
'Employees': 19600,
'Major Products': 'Mobile Chipsets, 5G Modems, IoT Solutions',
'Applications': 'Mobile, IoT, Consumer Electronics',
'Major Customers': 'Xiaomi, Oppo, Vivo, Amazon'
},
'Texas Instruments': {
'Funding Year': 1930,
'Employees': 34000,
'Major Products': 'Analog Chips, Embedded Processors',
'Applications': 'Industrial, Automotive, Personal Electronics',
'Major Customers': 'Boeing, Honeywell, Ford, Bosch'
},
'Applied Materials': {
'Funding Year': 1967,
'Employees': 35200,
'Major Products': 'Semiconductor Equipment, Display Equipment',
'Applications': 'Semiconductor Manufacturing, Display Manufacturing',
'Major Customers': 'TSMC, Intel, Samsung, Micron'
},
'Arm Holdings': {
'Funding Year': 1990,
'Employees': 7320,
'Major Products': 'ARM Architecture IP, Microprocessors',
'Applications': 'Mobile, Embedded, IoT, Automotive',
'Major Customers': 'Apple, Samsung, Qualcomm, Huawei'
},
'Micron Technology': {
'Funding Year': 1978,
'Employees': 48000,
'Major Products': 'Memory Chips (DRAM, NAND)',
'Applications': 'Mobile, Data Center, Automotive, Consumer Electronics',
'Major Customers': 'Dell, HP, Apple, Cisco'
},
'Analog Devices': {
'Funding Year': 1965,
'Employees': 26000,
'Major Products': 'Analog Chips, Mixed-Signal Chips, DSPs',
'Applications': 'Automotive, Industrial, Communication, Healthcare',
'Major Customers': 'Tesla, General Electric, Ford, Siemens'
},
'Lam Research': {
'Funding Year': 1980,
'Employees': 17450,
'Major Products': 'Semiconductor Manufacturing Equipment',
'Applications': 'Semiconductor Manufacturing',
'Major Customers': 'TSMC, Samsung, Micron, SK Hynix'
},
'KLA': {
'Funding Year': 1975,
'Employees': 15000,
'Major Products': 'Semiconductor Process Control Systems',
'Applications': 'Semiconductor Manufacturing, Process Control',
'Major Customers': 'Intel, TSMC, Samsung, GlobalFoundries'
},
'SK Hynix': {
'Funding Year': 1983,
'Employees': 31894,
'Major Products': 'Memory Chips (DRAM, NAND)',
'Applications': 'Mobile, Data Center, Consumer Electronics',
'Major Customers': 'Apple, Dell, Lenovo, HP'
},
'Tokyo Electron': {
'Funding Year': 1963,
'Employees': 17702,
'Major Products': 'Semiconductor Manufacturing Equipment',
'Applications': 'Semiconductor Manufacturing',
'Major Customers': 'TSMC, Samsung, Micron, Intel'
},
'Synopsys': {
'Funding Year': 1986,
'Employees': 20300,
'Major Products': 'Electronic Design Automation (EDA), Semiconductor IP',
'Applications': 'Semiconductor Design, Embedded Systems',
'Major Customers': 'Intel, TSMC, Samsung, Broadcom'
},
'Marvell Technology': {
'Funding Year': 1995,
'Employees': 6511,
'Major Products': 'Storage Controllers, Network Processors, SoCs',
'Applications': 'Data Center, Networking, Storage Solutions',
'Major Customers': 'Dell, Cisco, HP, Huawei'
}
}
# Define a function to fetch company data from yfinance
def get_company_data(ticker, company_name):
try:
stock = yf.Ticker(ticker)
info = stock.info
# Capture the current date
today = datetime.today().strftime('%Y-%m-%d')
# Check if predefined data exists for the company
if company_name in predefined_data:
data = predefined_data[company_name]
funding_year = data['Funding Year']
employees = data['Employees']
major_products = data['Major Products']
applications = data['Applications']
major_customers = data['Major Customers']
else:
funding_year = info.get('founded', None) # Company founding year
employees = info.get('fullTimeEmployees', None) # Number of employees
major_products = 'Technology' # Placeholder if not available
applications = 'Technology' # Placeholder if not available
major_customers = 'N/A' # Placeholder if not available
return {
'Date': today,
'Company Name': info.get('longName', ticker),
'Ticker': ticker,
'Industry': info.get('industry', 'Semiconductors'),
'Country': info.get('country', None),
'City': info.get('city', None),
'Website': info.get('website', None),
'Employees': employees,
'Funding Year': funding_year,
'Major Products': major_products,
'Applications': applications,
'Major Customers': major_customers
}
except Exception as e:
print(f"Error fetching data for {ticker}: {e}")
return None
# Initialize an empty list to store the data
company_data = []
# Loop through the tickers and get data
for company, ticker in tickers.items():
print(f"Fetching data for {company} ({ticker})...")
data = get_company_data(ticker, company)
if data:
company_data.append(data)
# Create a DataFrame
df = pd.DataFrame(company_data)
# Save the DataFrame to a CSV file in Google Drive
csv_file = os.path.join(data_path, 'semiconductor_companies_data_final.csv')
df.to_csv(csv_file, index=False)
print(f"Data saved to {csv_file}")
# 查詢 Nvidia 市值
import yfinance as yf
import pandas as pd
# Define the company ticker for Nvidia
ticker = 'NVDA'
# Fetch data for Nvidia from 2024-09-01 to 2024-10-16
nvidia_data = yf.download(ticker, start='2024-09-01', end='2025-09-16')
# Get company information for Nvidia (to find shares outstanding)
nvidia_info = yf.Ticker(ticker).info
shares_outstanding = nvidia_info['sharesOutstanding'] # Get the number of shares
# Calculate market cap (Market Cap = Close Price * Shares Outstanding)
nvidia_data['Market Cap (USD)'] = nvidia_data['Close'] * shares_outstanding
# Select relevant columns
nvidia_market_cap = nvidia_data[['Market Cap (USD)']]
# Save to CSV (optional, in Google Drive if mounted)
nvidia_market_cap.to_csv('/content/drive/My Drive/Semicon_Analysis/Nvidia_Market_Cap_2025-09-01_to_2025-09-16.csv')
# Display the data
nvidia_market_cap.head()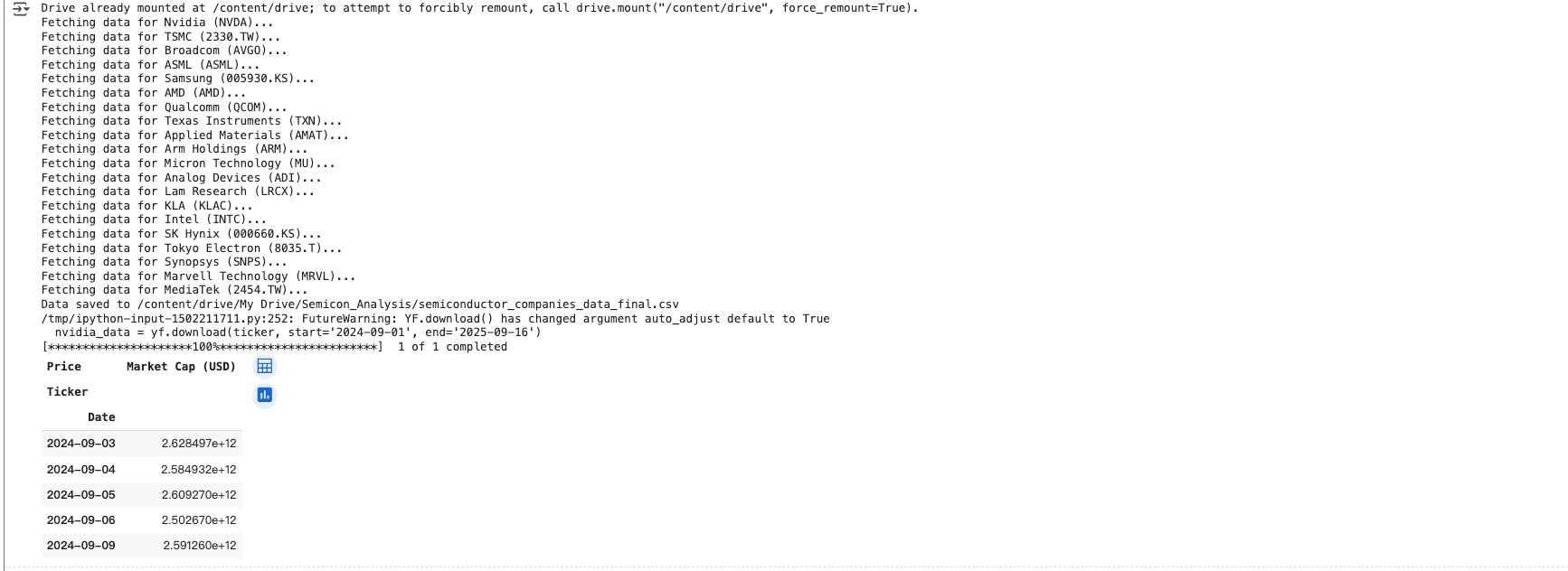
查詢 Nvidia 市值
import yfinance as yf
import pandas as pd
# Define the company ticker for Nvidia
ticker = 'NVDA'
# Fetch data for Nvidia from 2024-09-01 to 2025-09-23
nvidia_data = yf.download(ticker, start='2024-09-01', end='2025-09-23')
# Get company information for Nvidia (to find shares outstanding)
nvidia_info = yf.Ticker(ticker).info
shares_outstanding = nvidia_info['sharesOutstanding'] # Get the number of shares
# Calculate market cap (Market Cap = Close Price * Shares Outstanding)
nvidia_data['Market Cap (USD)'] = nvidia_data['Close'] * shares_outstanding
# Select relevant columns
nvidia_market_cap = nvidia_data[['Market Cap (USD)']]
# Save to CSV (optional, in Google Drive if mounted)
nvidia_market_cap.to_csv('/content/drive/My Drive/Semicon_Analysis/Nvidia_Market_Cap_2024-09-01_to_2024-10-16.csv')
# Display the data
nvidia_market_cap.head()匯率服務器(由於 forex 沒有 TWD 及 KRW, 本條刪除)
!pip install forex-python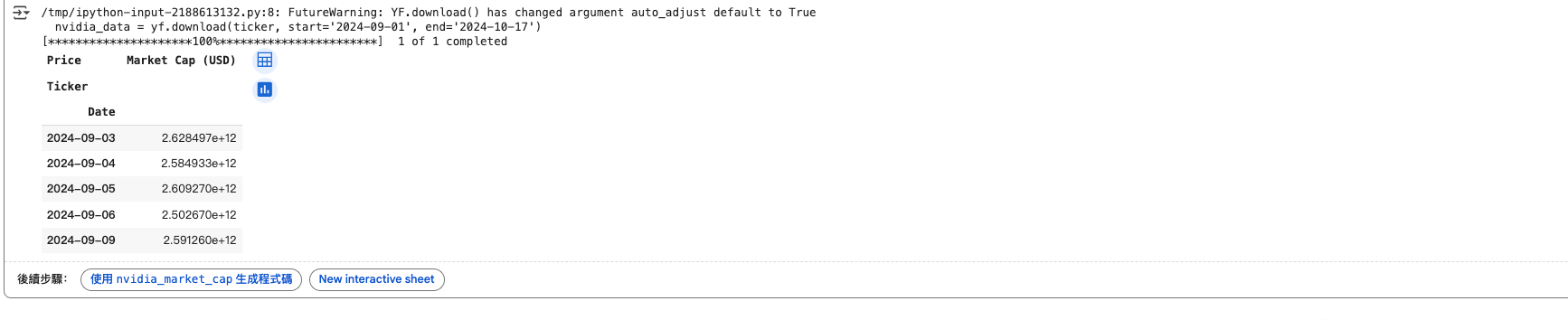
取得資料集
output_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_companies_data_final_1975-2025.csv'
#0923 New
# -*- coding: utf-8 -*-
import yfinance as yf
import pandas as pd
from datetime import datetime
# ========== 路徑 ==========
input_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_companies_data_final.csv'
output_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_companies_data_final_1975-2025.csv'
# ========== 讀取公司清單 ==========
company_data = pd.read_csv(input_file)
tickers = company_data['Ticker'].dropna().unique().tolist()
# ========== 幣別對照(未列者預設 USD)==========
currencies = {
'2330.TW': 'TWD', # TSMC
'005930.KS': 'KRW', # Samsung
'000660.KS': 'KRW', # SK hynix
'8035.T': 'JPY', # Tokyo Electron
}
def get_ccy(t):
return currencies.get(t, 'USD')
# 幣別 -> Yahoo 外匯代碼(USD/LCY:1 USD 可換多少本幣)
ccy_fx_symbol = {
'TWD': 'TWD=X',
'KRW': 'KRW=X',
'JPY': 'JPY=X',
}
# ========== 期間 ==========
start_date = '1975-01-01'
end_date = datetime.today().strftime('%Y-%m-%d')
# ========== 小工具:確保是一維 Series ==========
def ensure_series(x, index=None, name=None, to_numeric=True):
"""把任何輸入(Series/DataFrame/ndarray/scalar)強制轉成 1D pandas.Series。"""
if isinstance(x, pd.Series):
s = x.copy()
elif isinstance(x, pd.DataFrame):
s = x.iloc[:, 0].copy() if x.shape[1] else pd.Series(dtype='float64')
elif hasattr(x, 'values') and hasattr(x, 'index'):
s = pd.Series(x.values, index=x.index)
elif index is not None:
try:
s = pd.Series(list(x), index=index)
except Exception:
s = pd.Series([x] * len(index), index=index)
else:
s = pd.Series([x])
if to_numeric:
s = pd.to_numeric(s, errors='coerce')
if name is not None:
s.name = name
return s
# ========== 批次抓外匯 ==========
needed_ccy = sorted({get_ccy(t) for t in tickers if get_ccy(t) != 'USD'})
fx_symbols = sorted({ccy_fx_symbol[c] for c in needed_ccy if c in ccy_fx_symbol})
fx_close = pd.DataFrame()
if fx_symbols:
fx_raw = yf.download(
fx_symbols,
start=start_date,
end=end_date,
auto_adjust=False, # 取 Adj Close/Close
group_by='ticker',
progress=False
)
fx_close = pd.DataFrame(index=fx_raw.index)
for sym in fx_symbols:
if isinstance(fx_raw.columns, pd.MultiIndex):
if (sym, 'Adj Close') in fx_raw.columns:
fx_close[sym] = fx_raw[(sym, 'Adj Close')]
elif (sym, 'Close') in fx_raw.columns:
fx_close[sym] = fx_raw[(sym, 'Close')]
else:
col = 'Adj Close' if 'Adj Close' in fx_raw.columns else 'Close'
fx_close[sym] = fx_raw[col]
fx_close = fx_close.sort_index().ffill() # 前值補齊避免缺口
def get_shares_outstanding(tk: yf.Ticker):
"""盡量穩定地取得流通股數(float),失敗回傳 None。"""
# 優先 fast_info
try:
if hasattr(tk, 'fast_info') and tk.fast_info is not None:
shares = getattr(tk.fast_info, 'shares', None)
if shares and float(shares) > 0:
return float(shares)
except Exception:
pass
# 次之 info
try:
info = tk.info
shares = info.get('sharesOutstanding', None)
if shares and float(shares) > 0:
return float(shares)
except Exception:
pass
return None
all_frames = []
# ========== 逐檔計算 ==========
for ticker in tickers:
print(f"Processing {ticker} ...")
try:
px = yf.download(
ticker,
start=start_date,
end=end_date,
auto_adjust=False, # 我們使用 Adj Close 欄位
progress=False
)
if px.empty:
print(f" - No price data: {ticker}")
continue
# 取 Adj Close(若無則 Close),並強制為 Series
if 'Adj Close' in px.columns:
close_series = ensure_series(px['Adj Close'], name='Adj Close')
elif 'Close' in px.columns:
close_series = ensure_series(px['Close'], name='Close')
else:
print(f" - No Close/Adj Close columns: {ticker}")
continue
# 過濾異常價格(<=0 的值全剔除,避免負價造成負市值)
close_series = close_series[close_series > 0].dropna()
if close_series.empty:
print(f" - All prices invalid (<=0): {ticker}")
continue
# 取流通股數(合理性檢查)
tk = yf.Ticker(ticker)
shares = get_shares_outstanding(tk)
if not shares or shares <= 0:
print(f" - Skip (invalid sharesOutstanding): {ticker}")
continue
# 本幣市值
mktcap_lcy = ensure_series(close_series * shares, index=close_series.index, name='MKT_LCY')
# 幣別與換匯
ccy = get_ccy(ticker)
if ccy == 'USD':
mktcap_usd = mktcap_lcy
else:
sym = ccy_fx_symbol.get(ccy)
if (not sym) or fx_close.empty or (sym not in fx_close.columns):
print(f" - FX not available for {ticker} ({ccy}), USD will be NaN.")
mktcap_usd = pd.Series(index=mktcap_lcy.index, dtype='float64', name='MKT_USD')
else:
fx_series = ensure_series(
fx_close[sym].reindex(mktcap_lcy.index).ffill(),
index=mktcap_lcy.index, name=sym
)
# USD = 本幣 / (USD/本幣)
mktcap_usd = ensure_series(mktcap_lcy / fx_series, index=mktcap_lcy.index, name='MKT_USD')
# 組裝輸出(確保全為 1D)
out = pd.DataFrame(index=close_series.index)
out['Ticker'] = ticker # 標量自動廣播
out['Currency'] = ccy # 標量自動廣播
out['Close Price'] = ensure_series(close_series, index=close_series.index)
out['Market Cap (USD)'] = ensure_series(mktcap_usd, index=close_series.index)
out = out.reset_index().rename(columns={'index': 'Date'})
all_frames.append(out)
print(" - OK")
except Exception as e:
print(f" - Error {ticker}: {e}")
# ========== 輸出 ==========
if all_frames:
result = pd.concat(all_frames, ignore_index=True)
result = result.sort_values(['Ticker', 'Date']).drop_duplicates(subset=['Ticker', 'Date'])
result.to_csv(output_file, index=False)
print(f"✅ Market Cap data saved to {output_file}")
else:
print("⚠️ No data to save.")
合併數據集
output_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_0923.csv'
import yfinance as yf
import pandas as pd
import os
from forex_python.converter import CurrencyRates
from datetime import datetime
# Initialize forex converter
cr = CurrencyRates()
# Define file paths
input_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_companies_data_final.csv'
output_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_companies_data_final_1975-2025.csv'
# Read the existing CSV file with company data
company_data = pd.read_csv(input_file)
# Get the list of tickers and their currencies (assuming 'Ticker' and 'Country' columns)
tickers = company_data['Ticker'].tolist()
currencies = {
'2330.TW': 'TWD', # TSMC - Taiwan Dollar
'005930.KS': 'KRW', # Samsung - Korean Won
'000660.KS': 'KRW', # SK Hynix - Korean Won
'8035.T': 'JPY', # Tokyo Electron - Japanese Yen
# Add more tickers with non-USD currencies if needed
}
# Define the start and end dates for historical data
start_date = '1975-01-01'
end_date = datetime.today().strftime('%Y-%m-%d')
# Initialize an empty DataFrame to store market cap data for all companies
all_market_caps = pd.DataFrame()
# Loop through each ticker and get the historical market cap data
for ticker in tickers:
print(f"Fetching data for {ticker}...")
try:
# Download historical data
stock_data = yf.download(ticker, start=start_date, end=end_date)
company_info = yf.Ticker(ticker).info
shares_outstanding = company_info.get('sharesOutstanding', None)
if shares_outstanding:
# Calculate market cap in local currency
stock_data['Market Cap'] = stock_data['Close'] * shares_outstanding
# Check if the company is in a different currency
currency = currencies.get(ticker, 'USD') # Default to USD if not listed
stock_data['Currency'] = currency # Add currency column
if currency != 'USD':
# Convert market cap to USD using daily exchange rates
stock_data['Market Cap (USD)'] = stock_data.apply(
lambda row: cr.convert(currency, 'USD', row['Market Cap'], row.name), axis=1
)
else:
stock_data['Market Cap (USD)'] = stock_data['Market Cap']
# Add Close Price column
stock_data['Close Price'] = stock_data['Close']
# Add ticker to the data
stock_data['Ticker'] = ticker
all_market_caps = pd.concat([all_market_caps, stock_data[['Ticker', 'Close Price', 'Currency', 'Market Cap (USD)']]])
else:
print(f"Shares outstanding not available for {ticker}.")
except Exception as e:
print(f"Error fetching data for {ticker}: {e}")
# Reset index and save the data to a new CSV file
all_market_caps.reset_index(inplace=True)
all_market_caps.to_csv(output_file, index=False)
print(f"Market Cap data saved to {output_file}")
