1105_4.1 Deviation Chart 偏差圖

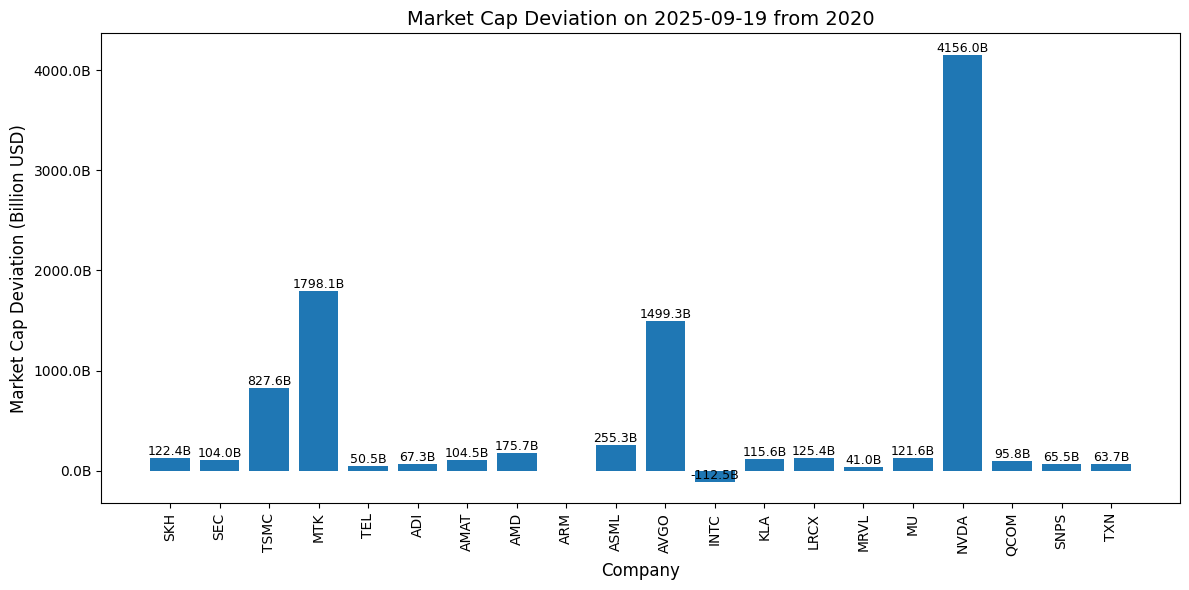
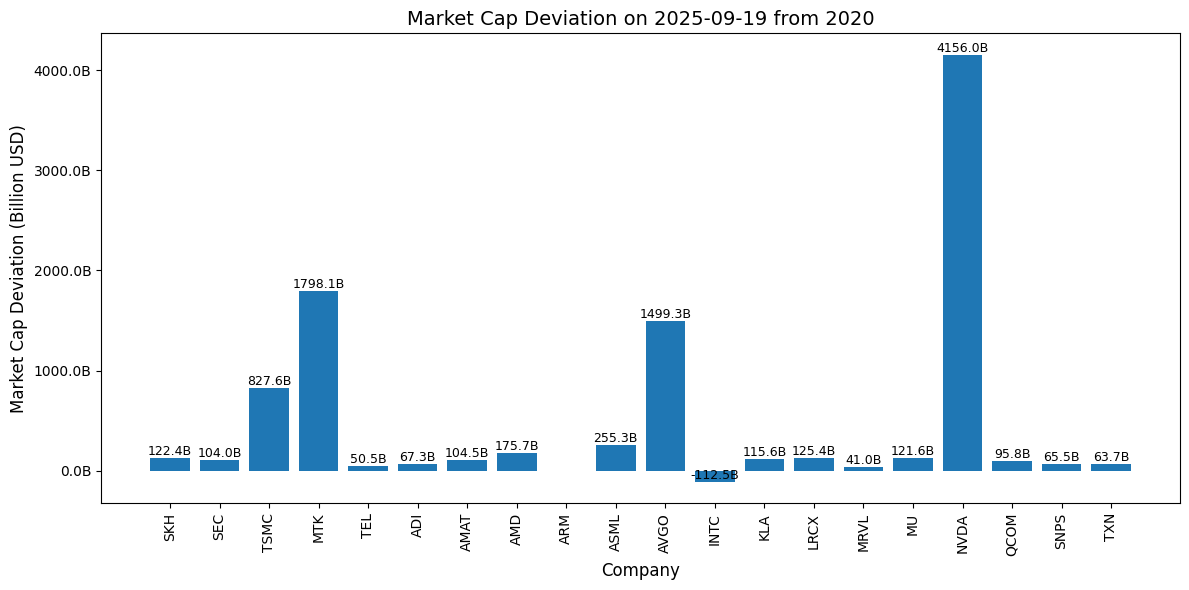
這張圖展示了各家半導體公司在 2025-09-19 相較於 2023 年年初 的 市值變動(Market Cap Deviation),數據單位是 十億美元(Billion USD)。這些變動數值顯示每家公司在這段時間內的市值增減情況。
圖表解釋:
- Y 軸:表示市值的變動值,以 十億美元 為單位。正值代表公司市值增加,負值代表公司市值下降。
- 例如,NVIDIA(NVDA)的市值增加了超過 4,156 億美元(4T USD 即 兆美元),這表明該公司在 2025 年的市場表現極其強勁。
- 其他公司如 TSMC 和 Broadcom(AVGO)也有較顯著的增長,但相比 NVIDIA,增幅較小。
- X 軸:表示各家公司。每家公司都以其簡稱(如 NVDA、TSMC、AVGO 等)表示。
- 公司如 NVIDIA(NVDA) 和 台積電(TSMC) 在這段時間內市值大幅增長。
- 反之,英特爾(INTC) 顯示了負的市值偏差,這意味著其市值在 2024 年減少了。
- 數值標籤:每個柱狀圖上方顯示的數字是對應公司的市值偏差,單位是 十億美元(Billion USD)。這些標籤能清楚地告訴你各家公司市值變動的具體數字。
- 例如,NVIDIA 增加了大約4.16兆美元,而 Intel 減少了約 1125 億美元。
整體解讀:
- 表現最佳的公司:NVIDIA 是這段時間市值增長最為顯著的公司,市值增加超過 4兆美元,顯示了其強勁的市場需求和技術領先。
- 其他增長公司:台積電(TSMC)和 Broadcom 也有顯著的增長,市值分別增加了幾百億美元。
- 表現較弱的公司:Intel 顯示了市值減少 1125億的情況,這表明該公司在市場上面臨挑戰,可能由於競爭加劇或技術落後等因素導致其市值下降。
使用這張圖的意義:
這張圖可以幫助你快速分析各家公司在 2020 年初至 2025年 09 月 19 日這段時間內的市場表現。你可以根據市值增減來判斷哪些公司在市場中取得了成功,哪些公司可能面臨挑戰。
Source Code
# 處理欄位
import pandas as pd
# 掛載 Google Drive(如果還沒有掛載)
from google.colab import drive
drive.mount('/content/drive')
# 讀取 CSV 文件
input_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_09231.csv'
df = pd.read_csv(input_file)
# 定義公司簡稱字典
company_abbr = {
'ASML Holding N.V.': 'ASML',
'Advanced Micro Devices, Inc.': 'AMD',
'Analog Devices, Inc.': 'ADI',
'Applied Materials, Inc.': 'AMAT',
'Arm Holdings plc': 'ARM',
'Broadcom Inc.': 'AVGO',
'Intel Corporation': 'INTC',
'KLA Corporation': 'KLA',
'Lam Research Corporation': 'LRCX',
'Marvell Technology, Inc.': 'MRVL',
'MediaTek Inc.': 'MTK',
'Micron Technology, Inc.': 'MU',
'NVIDIA Corporation': 'NVDA',
'QUALCOMM Incorporated': 'QCOM',
'SK hynix Inc.': 'SKH',
'Samsung Electronics Co., Ltd.': 'SEC',
'Synopsys, Inc.': 'SNPS',
'Taiwan Semiconductor Manufacturing Company Limited': 'TSMC',
'Texas Instruments Incorporated': 'TXN',
'Tokyo Electron Limited': 'TEL'
}
# 添加公司簡稱欄位
df['company_abbr'] = df['Company Name'].map(company_abbr)
# 檢查是否有任何公司名稱沒有找到對應的簡稱
missing_abbr = df[df['company_abbr'].isna()]['Company Name'].unique()
if len(missing_abbr) > 0:
print("下列公司名稱沒有找到對應的簡稱:")
print(missing_abbr)
# 將新的數據集存回到 CSV 文件
output_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_1017.csv'
df.to_csv(output_file, index=False)
print(f'新檔案已保存至: {output_file}')import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
# === 讀取 CSV 文件 ===
df = pd.read_csv('/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_09232.csv')
# 確保日期格式正確
df['Date'] = pd.to_datetime(df['Date'])
# === 設定基準年 ===
baseline_year = 2020
# 取出基準年年初的市值(1月第一筆交易資料)
baseline_market_cap = (
df[(df['Date'].dt.year == baseline_year) & (df['Date'].dt.month == 1)]
.sort_values(by='Date', ascending=True)
.groupby(['Ticker'])
.first()
.reset_index()[['Ticker', 'Market Cap (USD)']]
)
baseline_market_cap.rename(columns={'Market Cap (USD)': f'{baseline_year} Start Market Cap (USD)'}, inplace=True)
# 將基準年市值合併回原始 df
df = df.merge(baseline_market_cap, on='Ticker', how='left')
# 計算市值偏差 = 當前市值 - 基準年年初市值
df['Market Cap Deviation'] = df['Market Cap (USD)'] - df[f'{baseline_year} Start Market Cap (USD)']
# === 選擇最新日期的數據 ===
latest_date = df['Date'].max()
latest_df = df[df['Date'] == latest_date]
# === 繪製柱狀圖 ===
plt.figure(figsize=(12, 6))
bars = plt.bar(latest_df['company_abbr'], latest_df['Market Cap Deviation'])
# 設定圖表標題與軸標籤
plt.title(f'Market Cap Deviation on {latest_date.strftime("%Y-%m-%d")} from {baseline_year}', fontsize=14)
plt.xlabel('Company', fontsize=12)
plt.ylabel('Market Cap Deviation (Billion USD)', fontsize=12)
# 格式化 Y 軸為十億單位
plt.gca().yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f'{x*1e-9:.1f}B'))
# 旋轉 X 軸標籤避免重疊
plt.xticks(rotation=90)
# 在每個柱狀圖上方添加數值標籤(轉換為 Billion 顯示)
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval, f'{yval*1e-9:.1f}B',
ha='center', va='bottom', fontsize=9)
plt.tight_layout()
plt.show()