AZPVR |Stata|xtsemipar| Draft(8)


generate logaz=log(az100k)
. generate log_gdp=log(gdppp2017)
(194 missing values generated)
. generate log_pop65=log(pop_65y_pct)
(1 missing value generated)
. generate log_edu=log(primaryedu_year)
(22 missing values generated)
. generate log_hyperten=log(hyperten_100k)
. generate log_depress=log(depress100k)
. generate log_nonhdl=log(nonhdl_mgdl)
xi:xtsemipar az100k pop_65y_pct primaryedu_year hyperten_100k depress100k nonhdl_mgdl i.year,nonpar(gdppp2017) ci
i.year _Iyear_1990-2018 (naturally coded; _Iyear_1990 omitted)
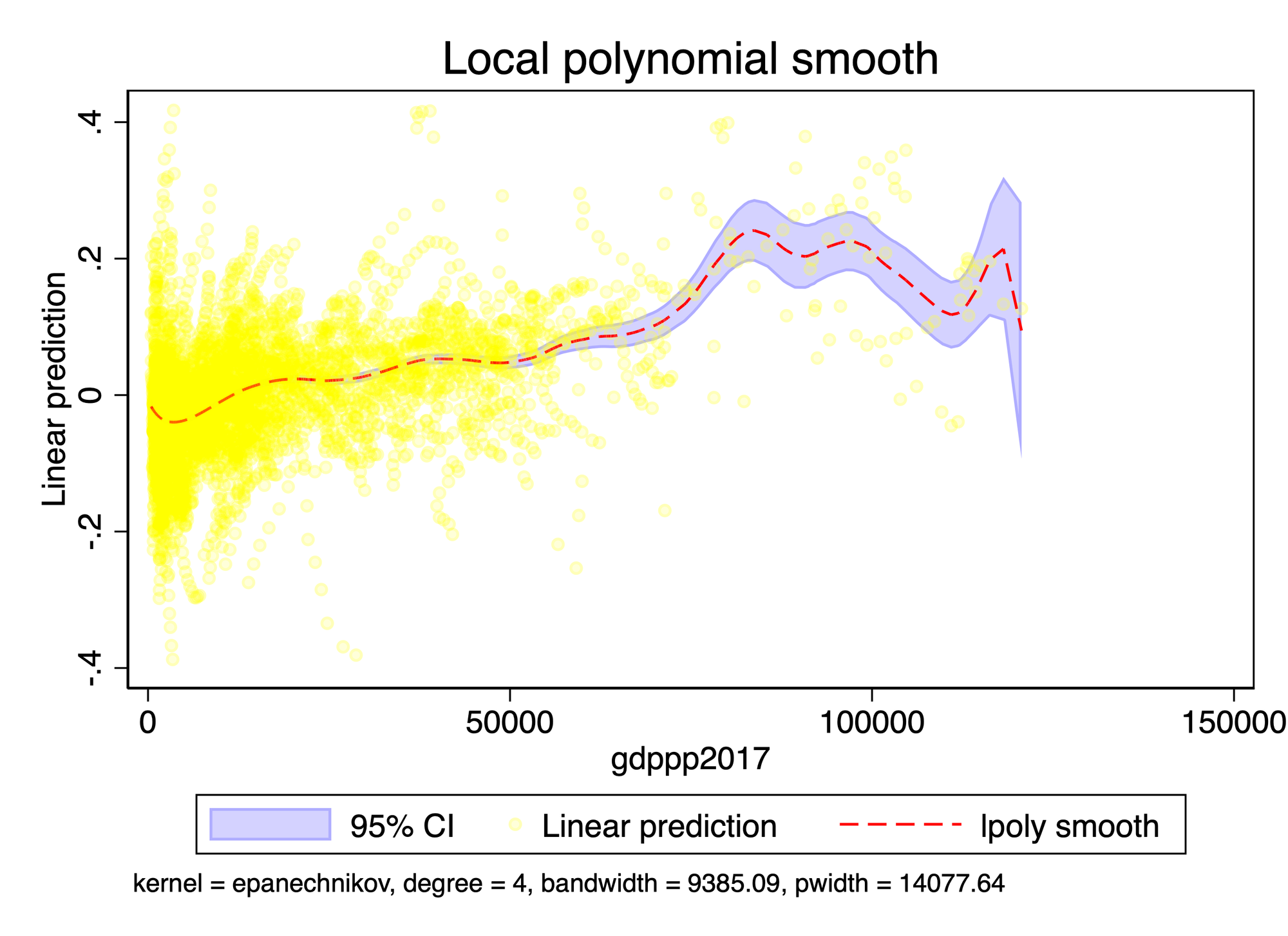
log AZ
xi:xtsemipar az100k pop_65y_pct primaryedu_year hyperten_100k depress100k nonhdl_mgdl i.year,nonpar(gdppp2017) ci
i.year _Iyear_1990-2018 (naturally coded; _Iyear_1990 omitted)
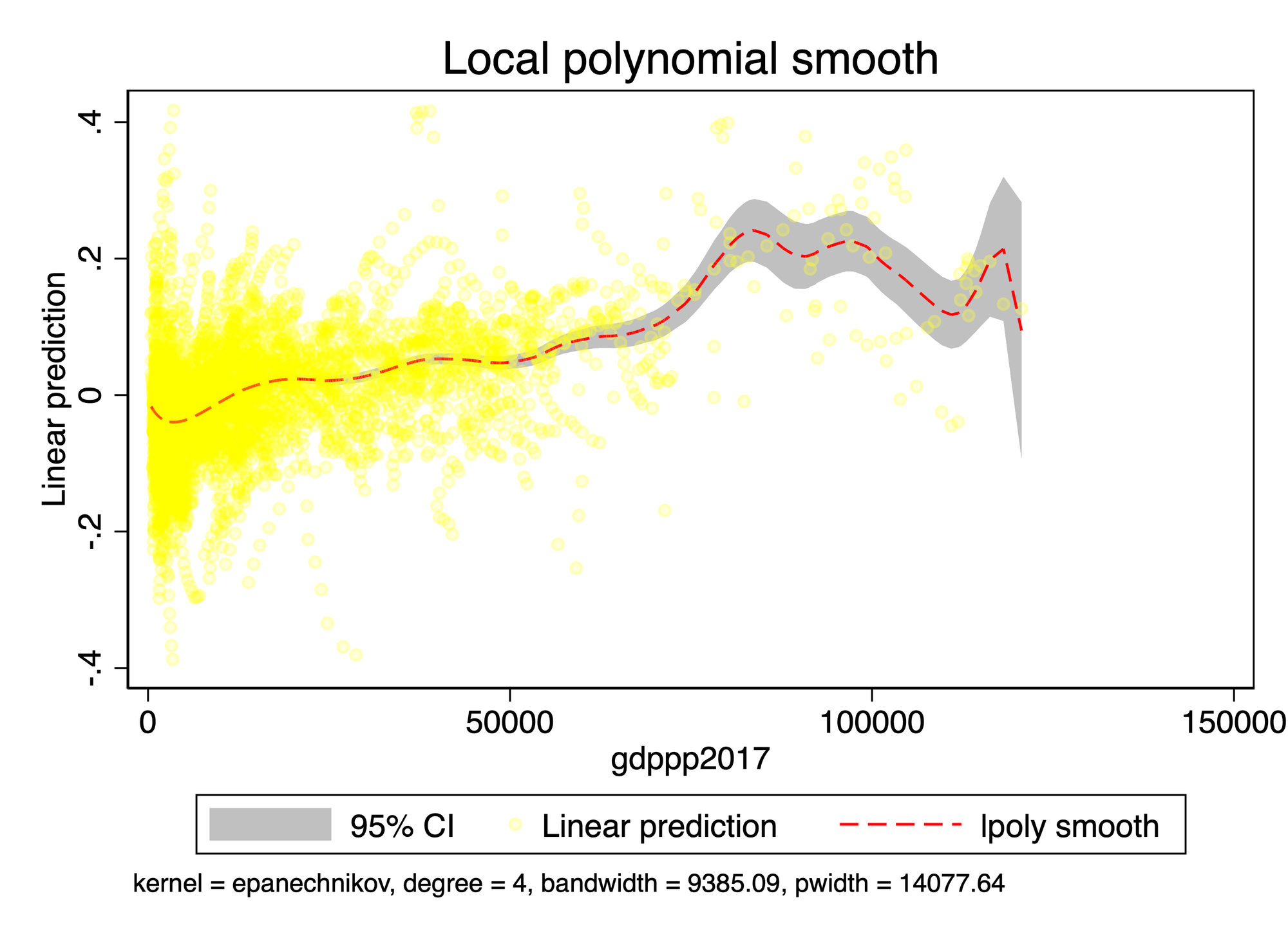
AZ_log Other Varians
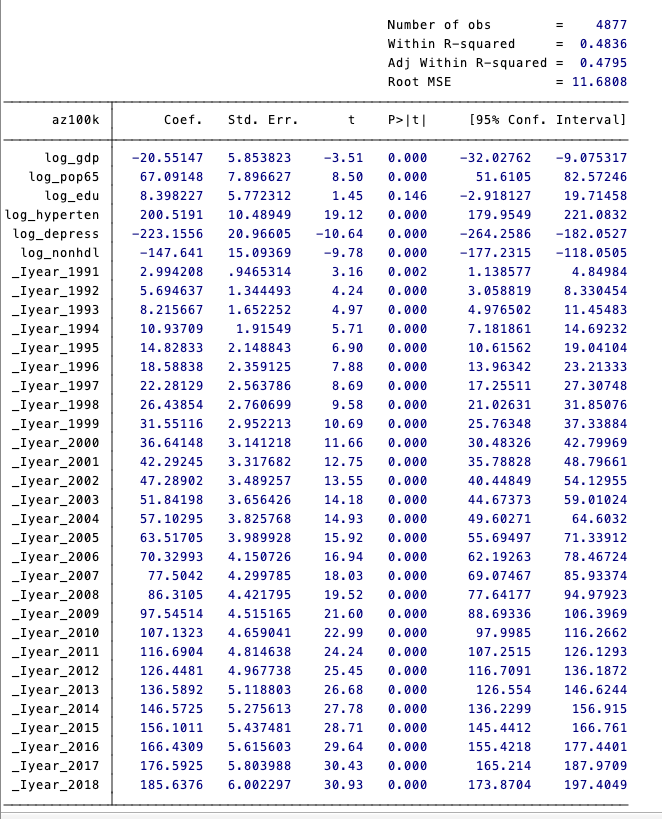
xi:xtsemipar az100k log_gdp log_pop65 log_edu log_hyperten log_depress log_nonhdl i.year,nonpar(gdppp2017) ci
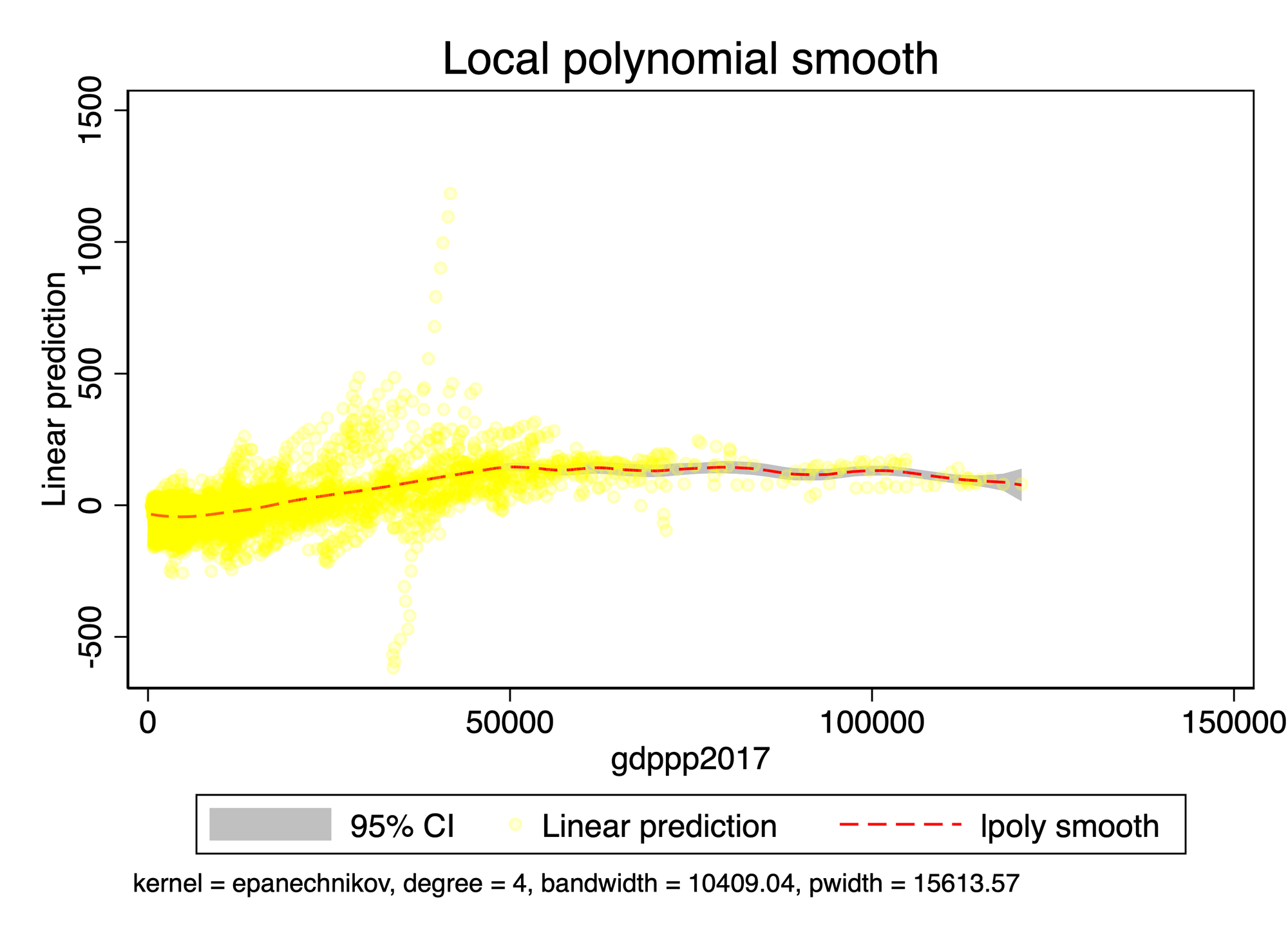
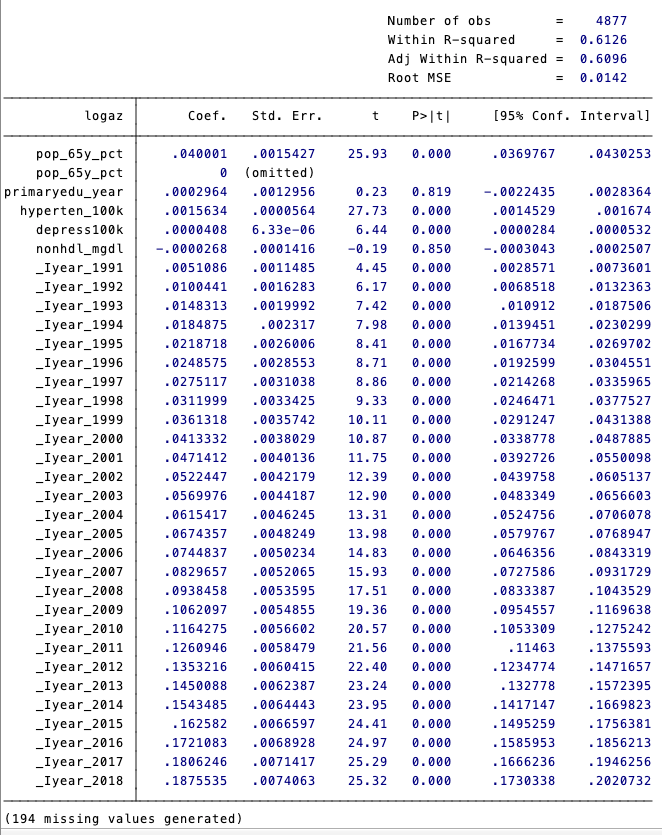
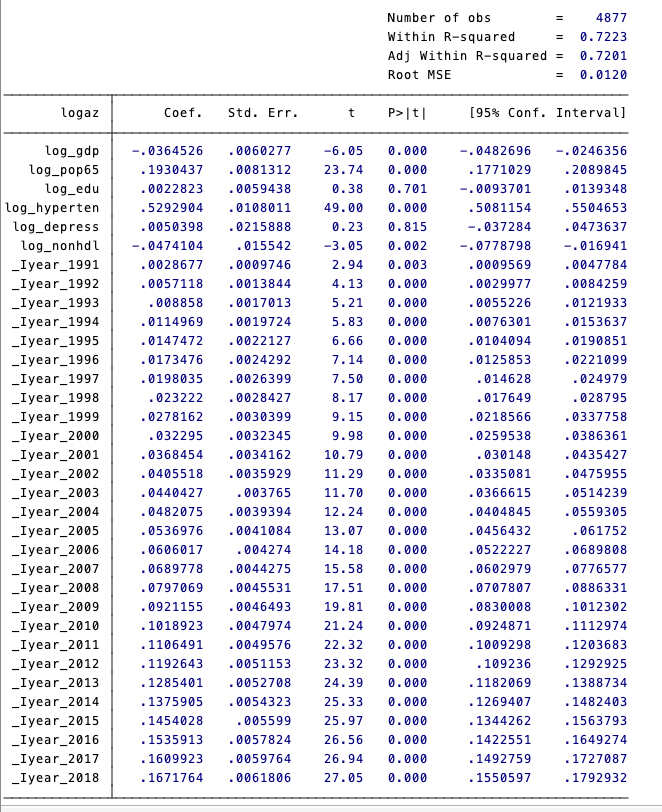
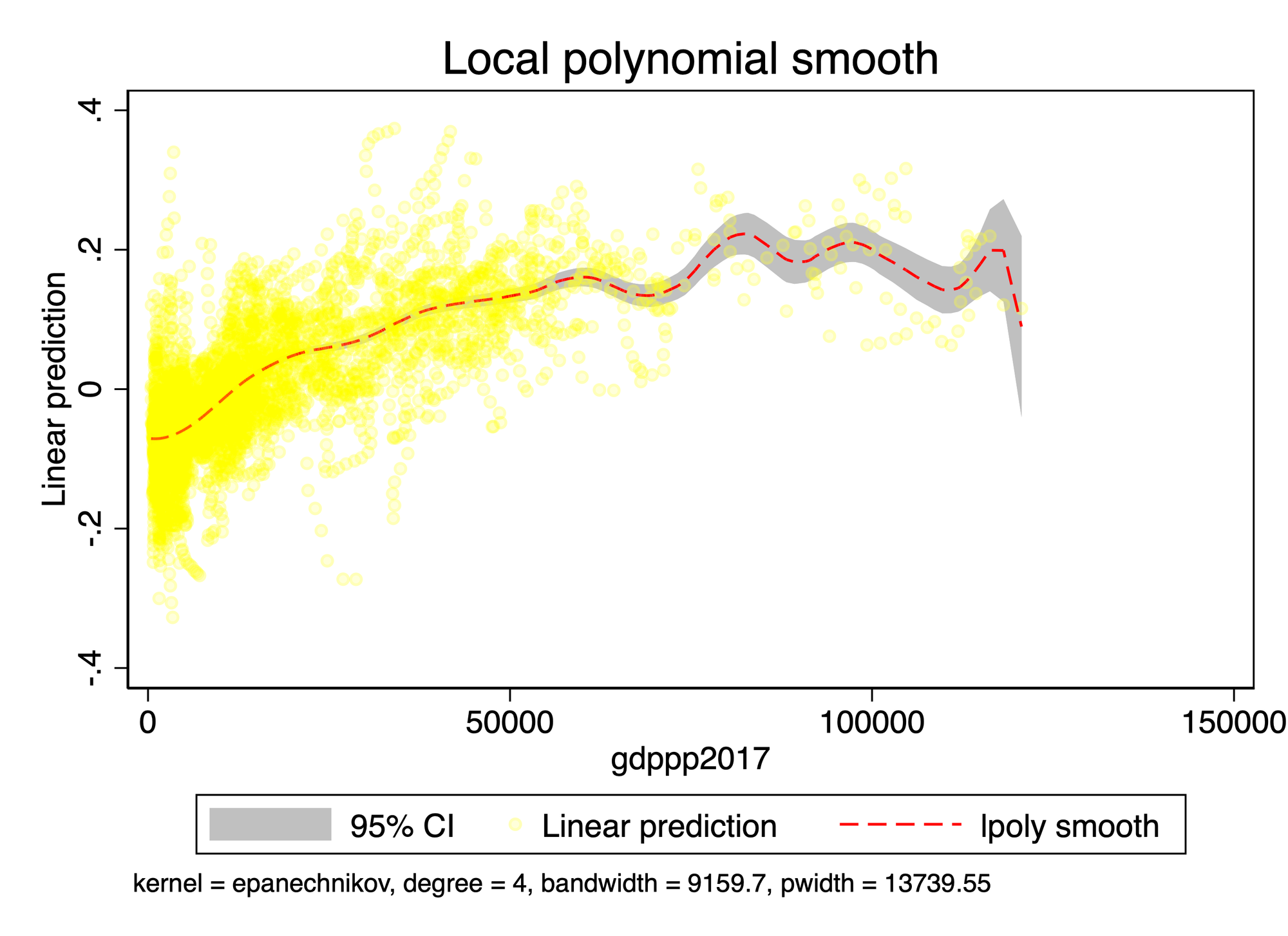
xi:xtsemipar logaz log_gdp log_pop65 log_edu log_hyperten log_depress log_nonhdl i.year,nonpar(gdppp2017) ci
i.year _Iyear_1990-2018 (naturally coded; _Iyear_1990 omitted)
定義
xtsemipar 是 Stata 中用於進行半母數回歸(semiparametric regression)分析的命令,特別適用於面板數據(panel data)。這種分析方法允許將某些變量作為參數變量處理,而將其他變量作為非參數變量處理,從而提供對數據中複雜非線性關係的靈活建模。
semipar 和 xtsemipar 的區別
semipar:用於橫截面數據的半參數回歸分析。它適合於單一時間點的數據,不考慮數據的時間維度。xtsemipar:用於面板數據的半參數回歸分析。面板數據包含了多個個體在多個時間點上的觀測值,xtsemipar允許同時考慮時間效應和個體效應,對於捕捉時間序列數據中的變化和個體間的異質性更有優勢。
如何解釋 strsemipar 回歸模型
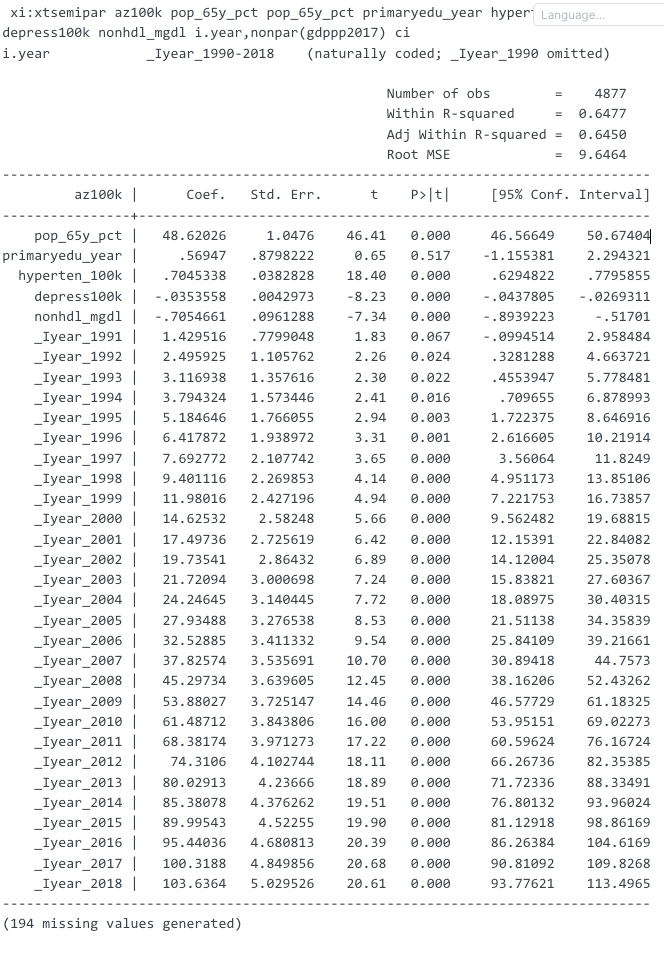
這張表是 xtsemipar 命令生成的回歸結果,顯示了阿爾茨海默病患病率(az100k)與其他變量之間的關係。以下是對表格中各部分的解釋:
- 回歸係數(Coef.):表示每個解釋變量對因變量(az100k)的影響。例如,pop_65y_pct 的係數為 48.62026,表示65歲及以上人口比例每增加一個單位,阿爾茨海默病患病率增加 48.62026。
- 標準誤(Std. Err.):表示回歸係數的估計標準誤差,用於衡量估計的不確定性。
- t值(t):係數除以其標準誤的結果,用於檢驗每個係數是否顯著不同於零。
- P值(P>|t|):表示係數在給定檢驗統計量下的顯著性水平。P值小於 0.05 表示該變量對因變量有顯著影響。
- 95%置信區間(95% Conf. Interval):表示在 95% 置信水平下,係數的估計範圍。例如,pop_65y_pct 的95%置信區間為 [46.56649, 50.67404]。
- R平方(R-squared)和調整後的R平方(Adj R-squared):表示模型的解釋力,越接近 1 表示模型的解釋力越強。
- Root MSE:均方根誤差,是觀測值與模型預測值之間差異的平方和的均值的平方根,用於衡量模型的預測精度。
具體解釋
- pop_65y_pct:65歲及以上人口比例顯著正向影響阿茲海默病患病率(係數 48.62026,P值 0.000)。
- primaryedu_year:初等教育年份對阿茲海默病患病率的影響不顯著(P值 0.517)。
- hyperten_100k 和 depress100k:每10萬人高血壓患病率和抑鬱症患病率都顯著影響阿茲海默病患病率(高血壓係數 0.7045338,P值 0.000;憂鬱症係數 -0.0353558,P值 0.000)。( 憂鬱症數據應該要再確認一次)
- 年份變量(_lyear):顯示了1991年至2018年各年份相對於基準年1990年的影響,大部分年份的影響均為顯著正向。
這些結果表明,高齡人口比例、高血壓和優鬱症患病率對阿茲海默病患病率有顯著影響,而教育年限的影響不顯著。
模型的高R平方值表明這些變量能夠很好地解釋阿爾茨海默病患病率的變異。