Boostrap sampling and estimation


在 Stata 中進行 10,000 次重複的引導回歸(Bootstrap Regression),並設置隨機種子為 123456
bootstrap _b, reps(10000) seed(123456): reg az100k pop_65y_pct primaryedu_year hyperten_100k depress100k nonhdl_mgdl i.year
這裡每部分的解釋是:
bootstrap _b:指定對回歸係數(_b)進行引導抽樣。reps(10000):表示進行 10,000 次重複抽樣。seed(123456):設置隨機種子,確保結果可重現。reg az100k pop_65y_pct primaryedu_year hyperten_100k depress100k nonhdl_mgdl i.year:這是回歸分析的命令,其中:az100k:依變數。pop_65y_pct primaryedu_year hyperten_100k depress100k nonhdl_mgdl:自變數。
Sample
bootstrap _b, reps(10000) seed(123456): reg az100k pop_65y_pct primaryedu_year hyperten_100k depress100k nonhdl_mgdl i.year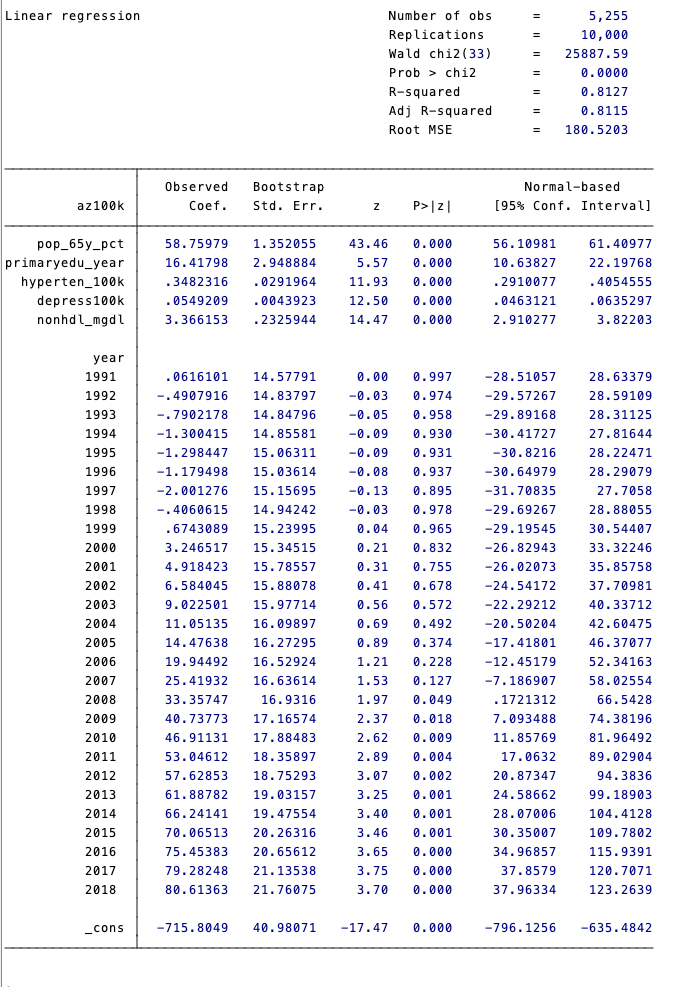
這張圖顯示了一個進行多元線性回歸分析的結果摘要。以下是對圖中數據的解讀:
- 依變數 (Dependent Variable):
az100k- 這可能表示每 100,000 人的盛行率。
- 模型統計數據:
- 觀察值數量 (Number of obs):560
- R-squared:0.6399 表示自變量可以解釋依變數變異的 63.99%。
- Adjusted R-squared:0.6375,這是調整後的 R 平方值,考慮了自變量的數量。
- Root MSE:161.4217,這是模型的標準誤差,表示預測值與實際值之間的平均差異。
- 回歸係數 (Coefficients):
pop_65y_pct:人口中 65 歲以上比例的回歸係數為 51.75932,標準誤差為 7.765772。P 值為 0.000,表示這個變數與依變數顯著相關。primaryedu_year、hyperten_100k、depress100k、nonhdl_mgdl均有其對應的係數和 P 值,其中depress100k的係數為 0.0833968,P 值小於 0.001,表示與依變數高度顯著相關。
- 時間變數 (Time Variables):
- 圖中列出了從 1990 年到 2018 年的每一年作為虛擬變數。這些變數顯示了不同年份相對於基準年份(1990 年)的影響。每個年份都有相應的係數和 P 值。大部分年份的 P 值較高,表明它們對依變數的影響不顯著。
- 統計顯著性:
- 統計顯著的係數(如
pop_65y_pct和depress100k)顯示這些變數對於az100k有顯著影響。對於不顯著的年份變數,我們可以認為那些年份與基準年份相比,對az100k沒有顯著的額外影響。
- 統計顯著的係數(如
總體來說,這個模型提供了一種估計多個變數對某個事件發生率的影響的方法,並顯示了時間趨勢在統計上大多數是不顯著的。
STATA website
Bootstrap sampling and estimation | Stata
Bootstrap sampling and estimation, including bootstrap of Stata commands, bootstrap of community-contributed programs, and standard errors and bias estimation
