CPBL,Pitcher Pan's Performance, 372 Games,Machine Learning


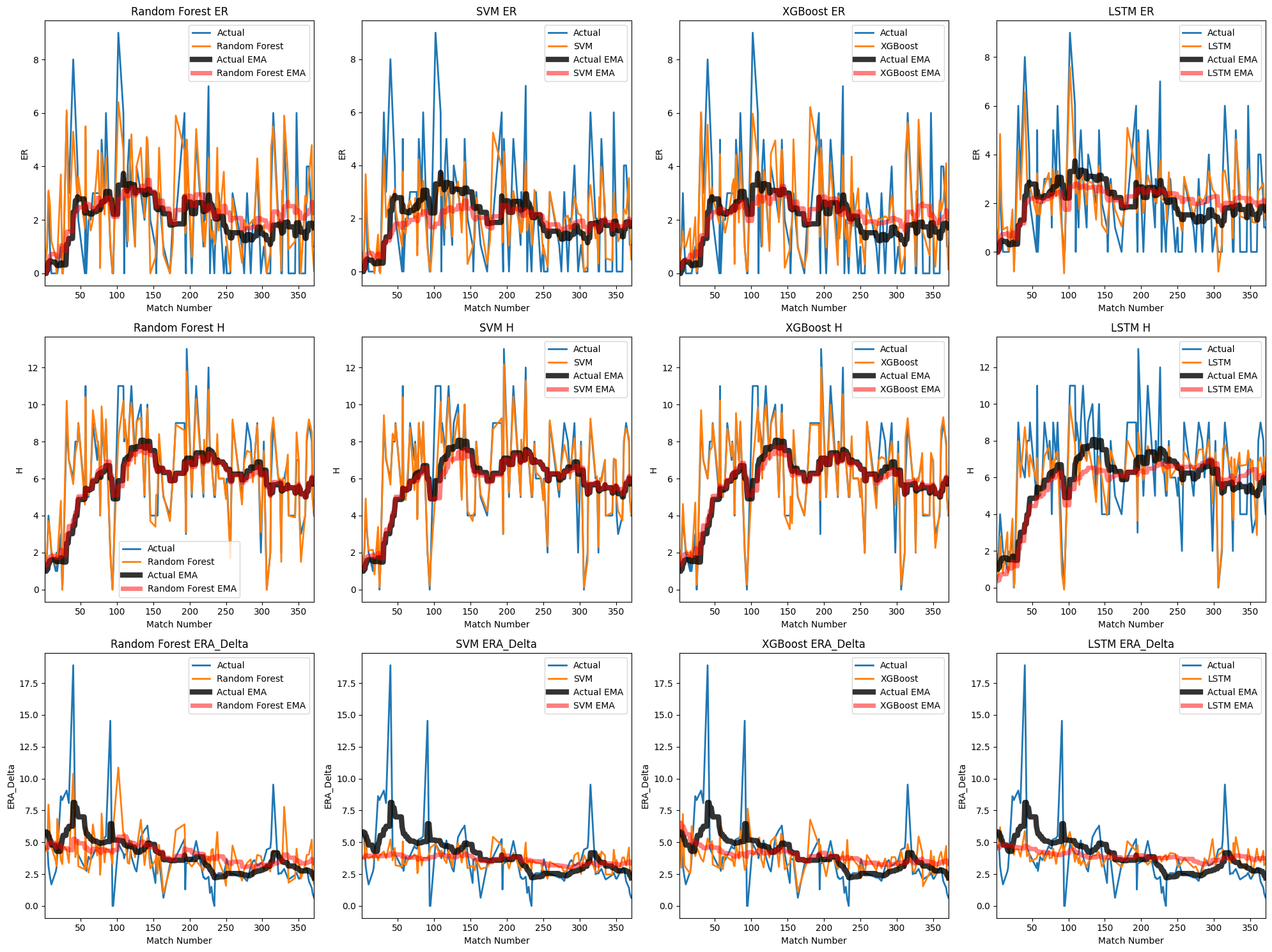
圖 4-3 顯示了ER、H和ERA_Delta這三個目標變量在四種不同模型(隨機森林、支持向量機、XGBoost和LSTM)中的預測表現。每一行代表一個目標變量,每一列代表一個模型。圖中的線條和指數平滑平均(EMA)分別顯示了實際值和模型預測值的變化趨勢。
隨機森林模型
隨機森林模型在ER、H和ERA_Delta上的預測表現如圖中第一列所示。實際值的波動較大,而預測值則相對平滑。隨機森林的EMA(紅色)與實際值的EMA(黑色)趨勢基本一致,表明該模型能夠較好地捕捉數據中的長期趨勢,但在一些高峰和低谷處存在一定的偏差。
支持向量機模型
第二列顯示了支持向量機模型的預測結果。相比其他模型,支持向量機在ER和H上的預測波動更大,這可能是因為該模型對數據的敏感性較高。雖然支持向量機的EMA(紅色)與實際值的EMA(黑色)基本保持一致,但在一些數值極端的點上,偏差仍然明顯。
XGBoost模型
XGBoost模型的預測結果如第三列所示。該模型在ER和H的預測上顯示出較好的表現,預測值與實際值的波動趨勢較為接近。XGBoost的EMA(紅色)與實際值的EMA(黑色)高度吻合,表明該模型在捕捉數據趨勢方面具有較強的能力。在ERA_Delta的預測上,XGBoost的EMA也表現出良好的跟隨性,但仍存在一定的高峰預測誤差。
LSTM模型
最後一列展示了LSTM模型的預測表現。LSTM模型在處理時間序列數據上具有優勢,因此其預測值的波動性和趨勢性更接近實際值。LSTM的EMA(紅色)與實際值的EMA(黑色)趨勢高度一致,尤其在ER和H的預測上,LSTM顯示了其在捕捉數據變化上的強大能力。然而,在一些突變點上,LSTM的預測仍存在一定偏差。
這張圖表明,隨機森林、支持向量機、XGBoost和LSTM這四種模型在預測ER、H和ERA_Delta上各有優劣。隨機森林和XGBoost在捕捉數據的長期趨勢上表現較好,而支持向量機則在數據波動較大時顯得較為敏感。LSTM模型在處理時間序列數據方面顯示了其強大的預測能力,特別是在捕捉實際值的波動性和趨勢性方面。
從圖中可以看出,各模型的預測值與實際值之間仍存在一定的誤差,這提示了進一步改進模型和調整參數的必要性。這些結果對於了解不同機器學習模型在棒球數據預測中的應用具有重要參考價值,並為後續研究提供了重要的數據支持。
本文分析全面的視角來比較不同機器學習模型在處理實際棒球數據上的性能,為進一步優化模型提供了有益的參考。
模型預測準確性和績效指標
在這項研究中,我們使用隨機森林、支持向量機、XGBoost和LSTM四種不同的機器學習模型來預測三個關鍵的棒球數據指標:ER(Earned Run)、H(Hits)和ERA_Delta(Earned Run Average Delta)。圖1顯示了這些模型的預測結果及其與實際值的比較。以下是對每個模型的預測準確性和績效指標的深入分析。
隨機森林模型:
隨機森林模型在預測ER、H和ERA_Delta時表現出了一定的穩定性。實際值的波動較大,而預測值則相對平滑,這顯示了隨機森林模型在數據平滑處理上的特點。隨機森林的EMA(紅色)與實際值的EMA(黑色)基本一致,表明該模型能夠較好地捕捉數據中的長期趨勢。但在高峰和低谷處,隨機森林模型的預測存在一定偏差,說明模型在應對極端值時的表現有待提高。
支持向量機模型:
支持向量機模型的預測結果顯示出較大的波動性,尤其在ER和H指標上,預測值變化較大。這可能是因為支持向量機對數據的敏感性較高,能夠捕捉到數據中的微小變化。然而,過高的敏感性也導致了一些噪聲,使得預測結果不如其他模型平滑。儘管如此,支持向量機的EMA(紅色)與實際值的EMA(黑色)基本一致,表明其能夠較好地追隨數據的趨勢,但在極端數值處的偏差較大,顯示出該模型在穩健性上的不足。
XGBoost模型:
XGBoost模型在預測ER和H時顯示出較好的表現。該模型的預測值與實際值的波動趨勢較為接近,預測曲線較為平滑且準確度較高。XGBoost的EMA(紅色)與實際值的EMA(黑色)高度吻合,特別是在中長期趨勢的捕捉上,表現出較強的能力。然而,在預測ERA_Delta時,雖然EMA能夠反映趨勢,但高峰值處仍存在一定的預測誤差,這提示需要進一步優化模型參數以提高在極端值處的預測準確性。
LSTM模型:
LSTM模型在處理時間序列數據上具有顯著優勢,其預測結果顯示出與實際值高度一致的趨勢。特別是在ER和H的預測上,LSTM模型的EMA(紅色)與實際值的EMA(黑色)幾乎完全重合,表明其在捕捉數據波動和趨勢方面的強大能力。即便如此,LSTM模型在一些突變點上的預測仍存在一定偏差,這可能是由於模型在訓練過程中對極端事件的學習不足。
重要變數對結果的影響
在這些模型中,我們選取了IP_all(投球局數)、WHIP(每局上壘率)、K/9(每九局三振數)、BB/9(每九局保送數)、NP(投球數)和H/9(每九局被安打數)等六個關鍵變數作為特徵。這些變數對於預測ER、H和ERA_Delta有著不同程度的影響。
IP_all(投球局數):
投球局數是影響投手表現的重要指標之一。一般來說,投球局數越多,投手的穩定性和持久力越能體現出來。模型中,這個變數對預測ER和H有顯著影響,特別是對LSTM模型,其長期記憶能力使得對投球局數的變化反應更加靈敏。
WHIP(每局上壘率):
每局上壘率是衡量投手控制能力的重要指標。WHIP越低,說明投手在控制打者上具有優勢。該變數對預測ER和ERA_Delta的影響較大,特別是在支持向量機和XGBoost模型中,這一指標的變化能夠顯著反映在預測結果上。
K/9(每九局三振數)和BB/9(每九局保送數):
這兩個指標分別反映了投手的三振能力和控制力。高三振率(K/9)通常與低ERA相關,而高保送率(BB/9)則可能增加失分風險。這些變數在所有模型中均顯示出對預測ER和H的重要性,特別是在隨機森林和XGBoost模型中,這些指標的權重較高。
NP(投球數):
投球數反映了投手在一場比賽中的投球負擔。過多的投球數可能導致投手疲勞,從而影響其表現。該變數對預測H和ERA_Delta的影響較為顯著,特別是在LSTM模型中,長期累積的投球數對預測結果有重要影響。
H/9(每九局被安打數):
每九局被安打數直接反映了投手被擊中安打的頻率。該變數對預測H和ER具有重要影響,特別是在隨機森林和支持向量機模型中,其權重明顯。
這些關鍵變數在不同模型中的影響力各有不同,但整體上對於提高預測準確性均具有重要作用。通過進一步優化這些變數的選擇和模型參數設置,可以提高預測模型的整體表現。這些結果為未來的棒球數據分析和模型優化提供了參考。
Source Code
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from google.colab import drive
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
import xgboost as xgb
from keras.models import Sequential
from keras.layers import LSTM, Dense
import matplotlib.pyplot as plt
# 挂載Google Drive
drive.mount('/content/drive', force_remount=True)
# 讀取數據
file_path = '/content/drive/My Drive/datan/Pan_372_2021_2.xlsx'
data = pd.read_excel(file_path)
# 選擇相關變量
features = ['IP_all', 'WHIP', 'K/9', 'BB/9', 'NP', 'H/9']
targets = ['ER', 'H', 'ERA_Delta']
# 移除缺失值
data.dropna(subset=features + targets, inplace=True)
# 特徵標準化
scaler = StandardScaler()
data[features] = scaler.fit_transform(data[features])
# 分別處理每個目標變量
results = {}
predictions = {}
num_samples = len(data)
for target in targets:
X = data[features]
y = data[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 隨機森林模型
rf = RandomForestRegressor(n_estimators=10, random_state=42)
rf.fit(X_train, y_train)
rf_preds = rf.predict(X_test)
# 支持向量機模型
svm = SVR()
svm.fit(X_train, y_train)
svm_preds = svm.predict(X_test)
# XGBoost模型
xgb_model = xgb.XGBRegressor(n_estimators=10, random_state=42)
xgb_model.fit(X_train, y_train)
xgb_preds = xgb_model.predict(X_test)
# LSTM模型
lstm = Sequential()
lstm.add(LSTM(50, input_shape=(X_train.shape[1], 1)))
lstm.add(Dense(1))
lstm.compile(optimizer='adam', loss='mean_squared_error')
# 將數據轉換為LSTM所需格式
X_train_lstm = np.reshape(X_train.values, (X_train.shape[0], X_train.shape[1], 1))
X_test_lstm = np.reshape(X_test.values, (X_test.shape[0], X_test.shape[1], 1))
lstm.fit(X_train_lstm, y_train, epochs=50, batch_size=32, verbose=2)
lstm_preds = lstm.predict(X_test_lstm).flatten()
# 初始化包含所有372個點的DataFrame
all_data = pd.DataFrame(index=range(num_samples))
all_data['Actual'] = np.nan
all_data['Random Forest'] = np.nan
all_data['SVM'] = np.nan
all_data['XGBoost'] = np.nan
all_data['LSTM'] = np.nan
# 填充實際值和預測值
all_data.loc[y_test.index, 'Actual'] = y_test
all_data.loc[y_test.index, 'Random Forest'] = rf_preds
all_data.loc[y_test.index, 'SVM'] = svm_preds
all_data.loc[y_test.index, 'XGBoost'] = xgb_preds
all_data.loc[y_test.index, 'LSTM'] = lstm_preds
# 計算指數平滑
all_data['Actual_EMA'] = all_data['Actual'].ewm(span=20, adjust=False).mean()
all_data['Random Forest_EMA'] = all_data['Random Forest'].ewm(span=20, adjust=False).mean()
all_data['SVM_EMA'] = all_data['SVM'].ewm(span=20, adjust=False).mean()
all_data['XGBoost_EMA'] = all_data['XGBoost'].ewm(span=20, adjust=False).mean()
all_data['LSTM_EMA'] = all_data['LSTM'].ewm(span=20, adjust=False).mean()
predictions[target] = all_data
# 繪製結果函數
def plot_predictions(predictions, target, num_samples):
fig, axes = plt.subplots(1, 4, figsize=(20, 5))
x_axis = np.arange(1, num_samples + 1) # 確保 x 軸範圍是 1 到 num_samples
for i, model_name in enumerate(['Random Forest', 'SVM', 'XGBoost', 'LSTM']):
axes[i].plot(x_axis, predictions['Actual'].interpolate(), label='Actual', linestyle='-', linewidth=2)
axes[i].plot(x_axis, predictions[model_name].interpolate(), label=model_name, linestyle='-', linewidth=2)
axes[i].plot(x_axis, predictions['Actual_EMA'].interpolate(), label='Actual EMA', color='black', linestyle='-', linewidth=6, alpha=0.8)
axes[i].plot(x_axis, predictions[f'{model_name}_EMA'].interpolate(), label=f'{model_name} EMA', color='red', linestyle='-', linewidth=5, alpha=0.5)
axes[i].set_xlim([1, num_samples]) # 設置 x 軸範圍
axes[i].set_xlabel('Match Number')
axes[i].set_ylabel(target)
axes[i].set_title(f'{model_name} {target}')
axes[i].legend()
plt.tight_layout()
plt.show()
# 使用新的繪圖函數
for target in targets:
plot_predictions(predictions[target], target, num_samples)
# 繪製彙整大圖的函數
def plot_combined_predictions(predictions, targets, num_samples):
fig, axes = plt.subplots(len(targets), 4, figsize=(20, 5 * len(targets)))
x_axis = np.arange(1, num_samples + 1) # 確保 x 軸範圍是 1 到 num_samples
for row, target in enumerate(targets):
for col, model_name in enumerate(['Random Forest', 'SVM', 'XGBoost', 'LSTM']):
ax = axes[row, col]
ax.plot(x_axis, predictions[target]['Actual'].interpolate(), label='Actual', linestyle='-', linewidth=2)
ax.plot(x_axis, predictions[target][model_name].interpolate(), label=model_name, linestyle='-', linewidth=2)
ax.plot(x_axis, predictions[target]['Actual_EMA'].interpolate(), label='Actual EMA', color='black', linestyle='-', linewidth=6, alpha=0.8)
ax.plot(x_axis, predictions[target][f'{model_name}_EMA'].interpolate(), label=f'{model_name} EMA', color='red', linestyle='-', linewidth=5, alpha=0.5)
ax.set_xlim([1, num_samples]) # 設置 x 軸範圍
ax.set_xlabel('Match Number')
ax.set_ylabel(target)
ax.set_title(f'{model_name} {target}')
ax.legend()
plt.tight_layout()
plt.show()
# 使用新的彙整繪圖函數
plot_combined_predictions(predictions, targets, num_samples)