LSTM.TAIEX.POC.0628.


dataset: MSCI top 30 company
from google.colab import drive
drive.mount('/content/drive')
!pip install yfinance scikit-learn matplotlib tensorflow
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
import matplotlib.dates as mdates
# 定義股票代碼和大盤指數
tickers = ["2330.TW", "2454.TW", "2317.TW", "2412.TW", "1303.TW", "2882.TW", "3008.TW", "2308.TW", "1402.TW",
"1216.TW", "2881.TW", "2891.TW", "2382.TW", "2409.TW", "1802.TW", "1101.TW", "3045.TW", "2324.TW",
"2105.TW", "2880.TW", "2887.TW", "2885.TW", "4904.TW", "2603.TW", "2884.TW", "2886.TW", "2357.TW",
"2344.TW", "4938.TW", "2888.TW", "^TWII"]
# 下載股票數據
data = yf.download(tickers, start="2021-01-01", end="2024-06-24")
# 使用前向填充處理缺失值
data = data.ffill()
# 提取調整後收盤價
adj_close = data['Adj Close']
# 計算日變動率
daily_change = adj_close.pct_change()
# 計算 Beta 值
def calculate_beta(stock_returns, market_returns, window):
cov_matrix = stock_returns.rolling(window).cov(market_returns)
var_market = market_returns.rolling(window).var()
beta = cov_matrix.div(var_market, axis=0)
return beta
# 市場回報率
market_returns = daily_change["^TWII"]
# 計算 Beta_120
beta_120 = daily_change.apply(lambda x: calculate_beta(x, market_returns, 120))
# 整合所有特徵變數
features = pd.DataFrame()
for ticker in tickers[:-1]: # 除去 "^TWII"
features[ticker] = beta_120[ticker]
# 使用前向填充處理缺失值
features = features.ffill()
# 确保没有 NaN 值
features = features.fillna(0)
# 設置目標變數
target = adj_close["^TWII"]
# 數據標準化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_features = scaler.fit_transform(features)
scaled_target = scaler.fit_transform(target.values.reshape(-1, 1))
# 确认没有出现nan值
print("Checking for NaN values in scaled_features and scaled_target:")
print(np.isnan(scaled_features).sum())
print(np.isnan(scaled_target).sum())
# 創建 LSTM 模型所需的數據集
def create_dataset(X, y, time_step=1):
Xs, ys = [], []
for i in range(len(X)-time_step):
Xs.append(X[i:(i+time_step), :])
ys.append(y[i + time_step])
return np.array(Xs), np.array(ys)
# 定義時間步長
time_step = 60
# 創建訓練和測試數據集
train_size = int(len(scaled_features) * 0.8)
X_train, y_train = create_dataset(scaled_features[:train_size], scaled_target[:train_size], time_step)
X_test, y_test = create_dataset(scaled_features[train_size:], scaled_target[train_size:], time_step)
# 确认没有出现nan值
print("Checking for NaN values in X_train and y_train:")
print(np.isnan(X_train).sum())
print(np.isnan(y_train).sum())
# 檢查數據集的大小
print(f"X_train shape: {X_train.shape}, y_train shape: {y_train.shape}")
print(f"X_test shape: {X_test.shape}, y_test shape: {y_test.shape}")
# 建立 LSTM 模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(time_step, X_train.shape[2])))
model.add(LSTM(50, return_sequences=False))
model.add(Dense(25))
model.add(Dense(1))
# 編譯模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 訓練模型
history = model.fit(X_train, y_train, batch_size=1, epochs=1)
# 確認訓練過程中沒有出現nan值
print("Checking for NaN values in training history:")
print(history.history['loss'])
# 預測
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 反標準化
train_predict = scaler.inverse_transform(train_predict)
test_predict = scaler.inverse_transform(test_predict)
y_train = scaler.inverse_transform(y_train.reshape(-1, 1))
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
# 調整索引和預測值的長度一致
train_predict_index = target.index[time_step:time_step + len(train_predict)]
test_predict_index = target.index[train_size + time_step:train_size + time_step + len(test_predict)]
# 檢查索引和預測值的形狀
print(f"train_predict_index shape: {train_predict_index.shape}")
print(f"train_predict shape: {train_predict.shape}")
print(f"test_predict_index shape: {test_predict_index.shape}")
print(f"test_predict shape: {test_predict.shape}")
# 繪製整個數據集的走勢圖
plt.figure(figsize=(14, 7))
plt.plot(target.index, target, color='blue', label='Actual TAIEX')
plt.plot(train_predict_index, train_predict, color='orange', label='Training Prediction')
plt.plot(test_predict_index, test_predict, color='green', label='Testing Prediction')
# 生成未來 180 天的預測
future_steps = 180
future_features = scaled_features[-time_step:]
future_features = np.expand_dims(future_features, axis=0)
future_predict = []
for i in range(future_steps):
pred = model.predict(future_features)
print(f"Step {i} - Prediction: {pred}") # 打印每一步的预测值
if np.isnan(pred).any(): # 检查预测值是否为 nan
print(f"Step {i} - Prediction contains nan values")
break
future_predict.append(pred[0])
pred = np.repeat(pred, future_features.shape[2]).reshape(1, 1, future_features.shape[2]) # 将pred调整为与future_features匹配的形状
future_features = np.append(future_features[:, 1:, :], pred, axis=1)
future_predict = np.array(future_predict)
print(f"future_predict shape: {future_predict.shape}") # 确认 future_predict 形状
print(f"future_predict data: {future_predict[:5]}") # 打印前5个预测数据以供检查
if future_predict.size > 0:
future_predict = scaler.inverse_transform(future_predict)
future_dates = pd.date_range(start=target.index[-1], periods=future_steps+1, inclusive='right')
print(f"future_dates: {future_dates}") # 确认 future_dates 的生成
plt.plot(future_dates, future_predict, color='red', label='Future Prediction')
# 設置 X 軸日期格式
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y/%m/%d'))
plt.gca().xaxis.set_major_locator(mdates.YearLocator())
plt.xticks(rotation=45, ha='right')
plt.xlabel('Date')
plt.ylabel('TAIEX')
plt.title('TAIEX Predict')
plt.legend()
plt.grid(True)
plt.show()
future_predict data: [[0.32367626]
[0.3314241 ]
[0.3407951 ]
[0.3496172 ]
[0.3574003 ]]
future_dates: DatetimeIndex(['2024-06-22', '2024-06-23', '2024-06-24', '2024-06-25',
'2024-06-26', '2024-06-27', '2024-06-28', '2024-06-29',
'2024-06-30', '2024-07-01',
...
'2024-12-09', '2024-12-10', '2024-12-11', '2024-12-12',
'2024-12-13', '2024-12-14', '2024-12-15', '2024-12-16',
'2024-12-17', '2024-12-18'],
dtype='datetime64[ns]', length=180, freq='D')
- tickers:
- 說明:包含所有股票代碼和大盤指數的列表。
- 類型:列表(List of Strings)。
- data:
- 說明:從 Yahoo Finance 下載的所有股票數據,包括開盤價、收盤價、最高價、最低價、調整後收盤價和交易量。
- 類型:DataFrame。
- adj_close:
- 說明:提取自
data的調整後收盤價。 - 類型:DataFrame。
- 說明:提取自
- daily_change:
- 說明:計算調整後收盤價的日變動率。
- 類型:DataFrame。
- market_returns:
- 說明:大盤指數的日變動率(以
^TWII表示)。 - 類型:Series。
- 說明:大盤指數的日變動率(以
- beta_120:
- 說明:計算的 Beta 值(120 天滾動窗口)。
- 類型:DataFrame。
- features:
- 說明:包含所有股票的 Beta 值,作為特徵變數。
- 類型:DataFrame。
- target:
- 說明:大盤指數的調整後收盤價,作為目標變數。
- 類型:Series。
- scaler:
- 說明:數據標準化的工具。
- 類型:MinMaxScaler。
- scaled_features:
- 說明:標準化後的特徵變數。
- 類型:Numpy Array。
- scaled_target:
- 說明:標準化後的目標變數。
- 類型:Numpy Array。
- time_step:
- 說明:LSTM 模型的時間步長。
- 類型:整數(Integer)。
- train_size:
- 說明:訓練數據集的大小,按比例劃分。
- 類型:整數(Integer)。
- X_train:
- 說明:LSTM 模型的訓練數據集。
- 類型:Numpy Array。
- y_train:
- 說明:LSTM 模型的訓練標籤。
- 類型:Numpy Array。
- X_test:
- 說明:LSTM 模型的測試數據集。
- 類型:Numpy Array。
- y_test:
- 說明:LSTM 模型的測試標籤。
- 類型:Numpy Array。
- model:
- 說明:LSTM 模型。
- 類型:Sequential。
- train_predict:
- 說明:模型對訓練數據集的預測結果。
- 類型:Numpy Array。
- test_predict:
- 說明:模型對測試數據集的預測結果。
- 類型:Numpy Array。
- train_predict_index:
- 說明:訓練預測結果的索引。
- 類型:DatetimeIndex。
- test_predict_index:
- 說明:測試預測結果的索引。
- 類型:DatetimeIndex。
- future_steps:
- 說明:未來預測的步數。
- 類型:整數(Integer)。
- future_features:
- 說明:未來預測的初始特徵數據。
- 類型:Numpy Array。
- future_predict:
- 說明:未來預測的結果。
- 類型:Numpy Array。
- future_dates:
- 說明:未來預測的日期範圍。
- 類型:DatetimeIndex。
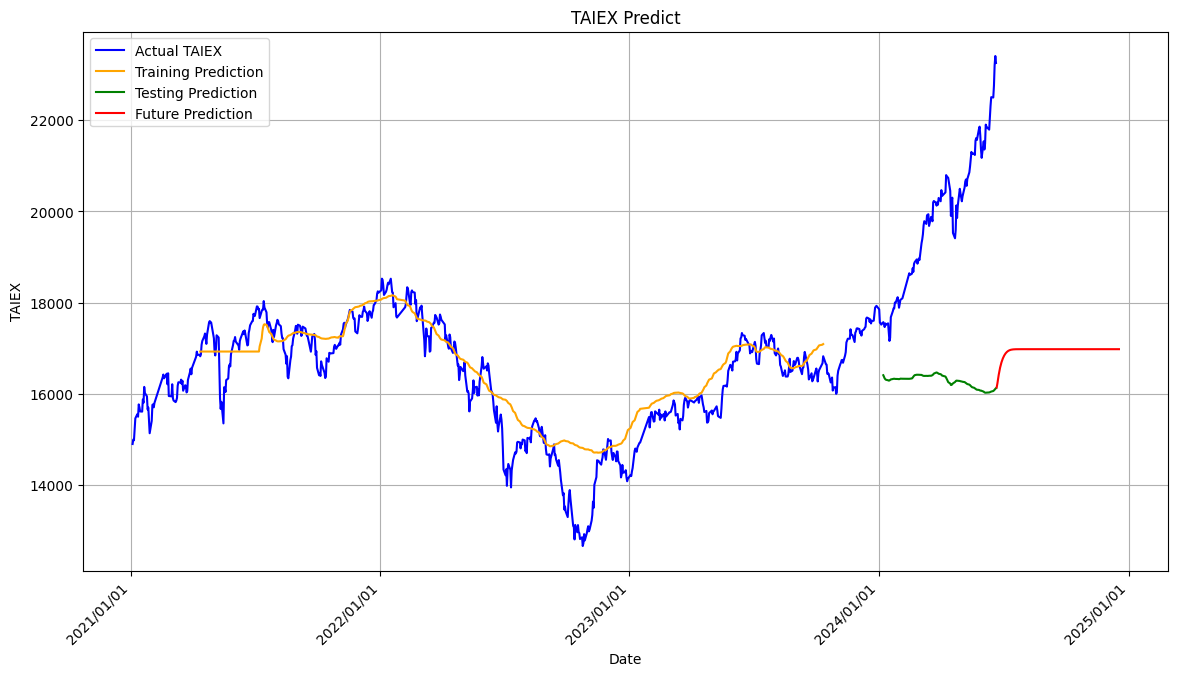
隨著 epochs 數量的增加,模型的損失(loss)應該逐漸減少,顯示出模型的性能正在改善。然而,過多的 epochs 也可能導致過擬合(overfitting),即模型在訓練數據上表現很好,但在測試數據上表現不佳。
因此,選擇合適的 epochs 數量是模型訓練中的一個重要決策。
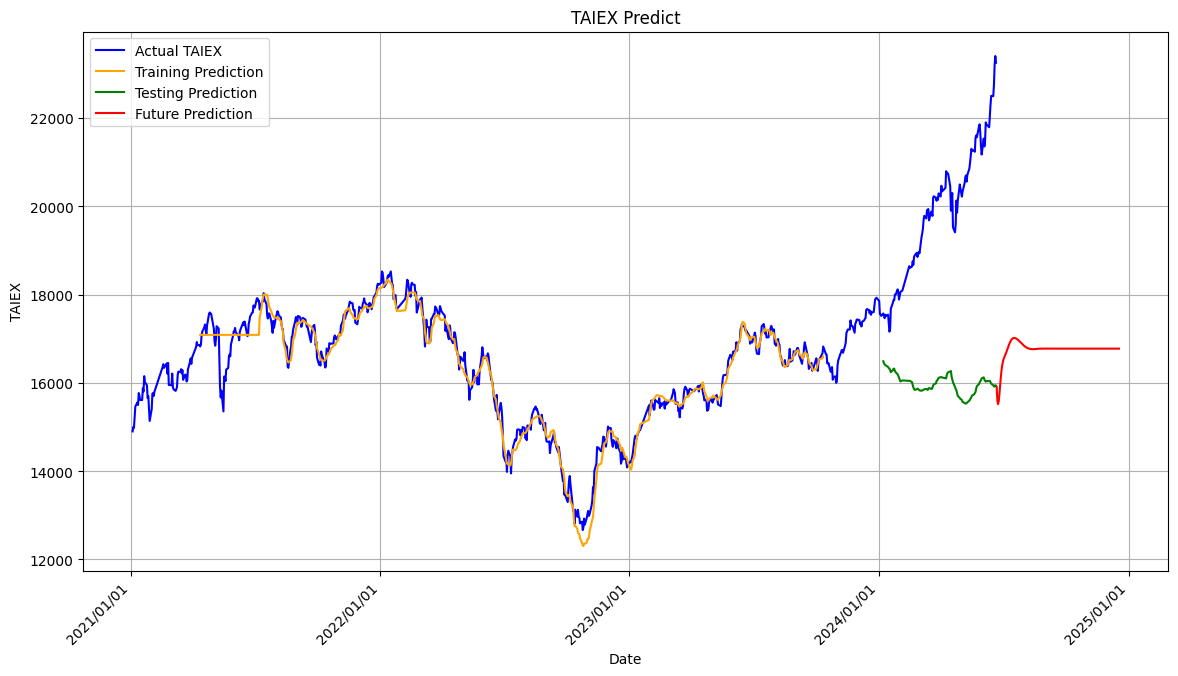
epochs 50.. 以下的 training prediction 不錯, 但後面的 testing 和 future prediction的離就很大
from google.colab import drive
drive.mount('/content/drive')
!pip install yfinance scikit-learn matplotlib tensorflow
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
import matplotlib.dates as mdates
# 定義股票代碼和大盤指數
tickers = ["2330.TW", "2454.TW", "2317.TW", "2412.TW", "1303.TW", "2882.TW", "3008.TW", "2308.TW", "1402.TW",
"1216.TW", "2881.TW", "2891.TW", "2382.TW", "2409.TW", "1802.TW", "1101.TW", "3045.TW", "2324.TW",
"2105.TW", "2880.TW", "2887.TW", "2885.TW", "4904.TW", "2603.TW", "2884.TW", "2886.TW", "2357.TW",
"2344.TW", "4938.TW", "2888.TW", "^TWII"]
# 下載股票數據
data = yf.download(tickers, start="2021-01-01", end="2024-06-24")
# 使用前向填充處理缺失值
data = data.ffill()
# 提取調整後收盤價
adj_close = data['Adj Close']
# 計算日變動率
daily_change = adj_close.pct_change()
# 計算 Beta 值
def calculate_beta(stock_returns, market_returns, window):
cov_matrix = stock_returns.rolling(window).cov(market_returns)
var_market = market_returns.rolling(window).var()
beta = cov_matrix.div(var_market, axis=0)
return beta
# 市場回報率
market_returns = daily_change["^TWII"]
# 計算 Beta_120
beta_120 = daily_change.apply(lambda x: calculate_beta(x, market_returns, 120))
# 整合所有特徵變數
features = pd.DataFrame()
for ticker in tickers[:-1]: # 除去 "^TWII"
features[ticker] = beta_120[ticker]
# 使用前向填充處理缺失值
features = features.ffill()
# 確保没有 NaN 值
features = features.fillna(0)
# 設置目標變數
target = adj_close["^TWII"]
# 數據標準化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_features = scaler.fit_transform(features)
scaled_target = scaler.fit_transform(target.values.reshape(-1, 1))
# 確認没有出現nan值
print("Checking for NaN values in scaled_features and scaled_target:")
print(np.isnan(scaled_features).sum())
print(np.isnan(scaled_target).sum())
# 創建 LSTM 模型所需的數據集
def create_dataset(X, y, time_step=1):
Xs, ys = [], []
for i in range(len(X)-time_step):
Xs.append(X[i:(i+time_step), :])
ys.append(y[i + time_step])
return np.array(Xs), np.array(ys)
# 定義時間步長
time_step = 60
# 創建訓練和測試數據集
train_size = int(len(scaled_features) * 0.8)
X_train, y_train = create_dataset(scaled_features[:train_size], scaled_target[:train_size], time_step)
X_test, y_test = create_dataset(scaled_features[train_size:], scaled_target[train_size:], time_step)
# 確認没有出現nan值
print("Checking for NaN values in X_train and y_train:")
print(np.isnan(X_train).sum())
print(np.isnan(y_train).sum())
# 檢查數據集的大小
print(f"X_train shape: {X_train.shape}, y_train shape: {y_train.shape}")
print(f"X_test shape: {X_test.shape}, y_test shape: {y_test.shape}")
# 建立 LSTM 模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(time_step, X_train.shape[2])))
model.add(LSTM(50, return_sequences=False))
model.add(Dense(25))
model.add(Dense(1))
# 編譯模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 訓練模型
history = model.fit(X_train, y_train, batch_size=1, epochs=50)
# 確認訓練過程中没有出現nan值
print("Checking for NaN values in training history:")
print(history.history['loss'])
# 預測
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 反標準化
train_predict = scaler.inverse_transform(train_predict)
test_predict = scaler.inverse_transform(test_predict)
y_train = scaler.inverse_transform(y_train.reshape(-1, 1))
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
# 調整索引和預測值的長度一致
train_predict_index = target.index[time_step:time_step + len(train_predict)]
test_predict_index = target.index[train_size + time_step:train_size + time_step + len(test_predict)]
# 確認索引和預測值的形狀
print(f"train_predict_index shape: {train_predict_index.shape}")
print(f"train_predict shape: {train_predict.shape}")
print(f"test_predict_index shape: {test_predict_index.shape}")
print(f"test_predict shape: {test_predict.shape}")
# 繪製整個數據集的走勢圖
plt.figure(figsize=(14, 7))
plt.plot(target.index, target, color='blue', label='Actual TAIEX')
plt.plot(train_predict_index, train_predict, color='orange', label='Training Prediction')
plt.plot(test_predict_index, test_predict, color='green', label='Testing Prediction')
# 生成未來 180 天的預測
future_steps = 180
future_features = scaled_features[-time_step:]
future_features = np.expand_dims(future_features, axis=0)
future_predict = []
for i in range(future_steps):
pred = model.predict(future_features)
print(f"Step {i} - Prediction: {pred}") # 打印每一步的预测值
if np.isnan(pred).any(): # 檢查预测值是否為 nan
print(f"Step {i} - Prediction contains nan values")
break
future_predict.append(pred[0])
pred = np.repeat(pred, future_features.shape[2]).reshape(1, 1, future_features.shape[2]) # 将pred调整为与future_features匹配的形狀
future_features = np.append(future_features[:, 1:, :], pred, axis=1)
future_predict = np.array(future_predict)
print(f"future_predict shape: {future_predict.shape}") # 確認 future_predict 形狀
print(f"future_predict data: {future_predict[:5]}") # 打印前5个预测数据以供检查
if future_predict.size > 0:
future_predict = scaler.inverse_transform(future_predict)
future_dates = pd.date_range(start=target.index[-1], periods=future_steps+1, inclusive='right')
print(f"future_dates: {future_dates}") # 確認 future_dates 的生成
plt.plot(future_dates, future_predict, color='red', label='Future Prediction')
# 設置 X 軸日期格式
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y/%m/%d'))
plt.gca().xaxis.set_major_locator(mdates.YearLocator())
plt.xticks(rotation=45, ha='right')
plt.xlabel('Date')
plt.ylabel('TAIEX')
plt.title('TAIEX Predict')
plt.legend()
plt.grid(True)
plt.show()