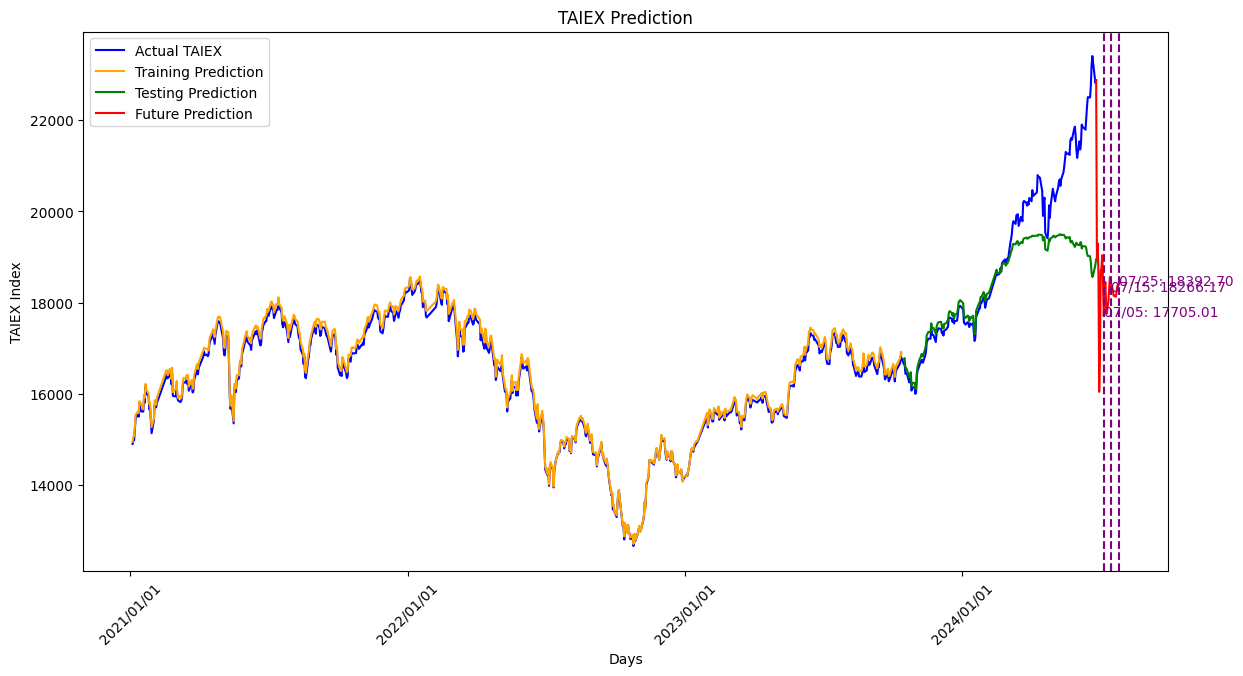
LSTM_TAIEX_0628


training 能力不好,要再調
特徵變數(Features)
特徵變數是用來預測目標變數的獨立變數。在這個例子中,特徵變數包括以下幾個部分:
- Open: 當日的開盤價。
- High: 當日的最高價。
- Low: 當日的最低價。
- Close: 當日的收盤價。
- Adj Close: 經過調整的收盤價,考慮了股息和拆股等因素。
- Volume: 當日的交易量。
- Daily Change: 當日收盤價的日變動率,計算公式為 (當日收盤價 - 前一日收盤價) / 前一日收盤價。
- Beta_60: 過去60天的Beta值,用於衡量股票相對於大盤的波動性。
- Beta_120: 過去120天的Beta值,用於衡量股票相對於大盤的波動性。
目標變數(Target)
目標變數是我們想要預測的變數。在這個例子中,目標變數為:
- Adj Close: 台灣加權股價指數(TAIEX)的調整後收盤指數。
處理缺失值
為了處理缺失值,我們使用了前向填充(forward fill)和後向填充(backward fill)的方法來填補數據中的空缺,確保數據的完整性。這樣的處理方式能夠最大程度上保持數據的連續性和一致性。
數據摘要
以下是特徵變數的摘要:
- Open
- 描述: 當日的開盤價。
- 類型: 浮點數
- High
- 描述: 當日的最高價。
- 類型: 浮點數
- Low
- 描述: 當日的最低價。
- 類型: 浮點數
- Close
- 描述: 當日的收盤價。
- 類型: 浮點數
- Adj Close
- 描述: 經過調整的收盤價,考慮了股息和拆股等因素。
- 類型: 浮點數
- Volume
- 描述: 當日的交易量。
- 類型: 整數
- Daily Change
- 描述: 當日收盤價的日變動率,計算公式為 (當日收盤價 - 前一日收盤價) / 前一日收盤價。
- 類型: 浮點數
- Beta_60
- 描述: 過去60天的Beta值,用於衡量股票相對於大盤的波動性。
- 類型: 浮點數
- Beta_120
- 描述: 過去120天的Beta值,用於衡量股票相對於大盤的波動性。
- 類型: 浮點數
目標變數摘要:
- Adj Close
- 描述: 台灣加權股價指數(TAIEX)的調整後收盤指數。
- 類型: 浮點數
數據處理
- 填補缺失值:使用前向填充和後向填充來填補數據中的空缺。
- 正規化數據:使用
MinMaxScaler將特徵和目標變數縮放到[0, 1]範圍內,這有助於提高LSTM模型的訓練效果。 - 轉換數據形狀:將數據轉換為LSTM模型所需的形狀。
這些特徵變數和目標變數共同構成了模型的訓練和測試數據,用於預測台灣加權股價指數(TAIEX)的未來走勢。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout, Bidirectional
from sklearn.preprocessing import MinMaxScaler
from google.colab import drive
import datetime
# 授權 Google Drive
drive.mount('/content/drive')
# 定義下載資料的函數
def download_data(ticker, start_date):
data = yf.download(ticker, start=start_date)
data['Return'] = data['Adj Close'].pct_change()
data['Trade Amount'] = data['Volume'] * data['Adj Close'] # 个股成交量(金額)
data['MA7'] = data['Adj Close'].rolling(window=7).mean()
data['MA21'] = data['Adj Close'].rolling(window=21).mean()
data['RSI14'] = calculate_rsi(data['Adj Close'], 14)
data['Beta_60'] = calculate_beta(data['Return'], data['Return'].rolling(window=60).mean(), 60)
data['Beta_120'] = calculate_beta(data['Return'], data['Return'].rolling(window=120).mean(), 120)
return data
def calculate_rsi(series, period):
delta = series.diff(1)
gain = (delta.where(delta > 0, 0)).rolling(window=period).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=period).mean()
rs = gain / loss
rsi = 100 - (100 / (1 + rs))
return rsi
def calculate_beta(stock_returns, market_returns, window):
cov_matrix = stock_returns.rolling(window=window).cov(market_returns)
market_variance = market_returns.rolling(window=window).var()
beta = cov_matrix / market_variance
return beta
# 下載台股指數和個股資料
tickers = ["^TWII"]
data = {ticker: download_data(ticker, "2021-01-01") for ticker in tickers}
# 將資料保存為CSV文件到Google Drive
for ticker in tickers:
data[ticker].to_csv(f"/content/drive/My Drive/{ticker}.csv")
# 構建模型的資料集
stock_data = data["^TWII"]
stock_data['Daily Change'] = stock_data['Adj Close'].pct_change()
features = stock_data[['Open', 'High', 'Low', 'Close', 'Adj Close', 'Volume', 'Daily Change', 'Trade Amount', 'MA7', 'MA21', 'RSI14', 'Beta_60', 'Beta_120']]
target = stock_data[['Adj Close']]
# 去除目標變數為0的資料
mask = target['Adj Close'] != 0
features = features[mask]
target = target[mask]
# 填充缺失值
features.fillna(method='ffill', inplace=True)
features.fillna(method='bfill', inplace=True)
target.fillna(method='ffill', inplace=True)
target.fillna(method='bfill', inplace=True)
# 分割訓練集和測試集
train_size = int(len(features) * 0.8)
X_train, X_test = features[:train_size], features[train_size:]
y_train, y_test = target[:train_size], target[train_size:]
# 正規化資料
feature_scaler = MinMaxScaler()
target_scaler = MinMaxScaler()
X_train_scaled = feature_scaler.fit_transform(X_train)
X_test_scaled = feature_scaler.transform(X_test)
y_train_scaled = target_scaler.fit_transform(y_train.values.reshape(-1, 1))
y_test_scaled = target_scaler.transform(y_test.values.reshape(-1, 1))
# 轉換成LSTM需要的形狀
X_train_scaled = X_train_scaled.reshape((X_train_scaled.shape[0], 1, X_train_scaled.shape[1]))
X_test_scaled = X_test_scaled.reshape((X_test_scaled.shape[0], 1, X_test_scaled.shape[1]))
# 構建LSTM模型
model = Sequential()
model.add(Bidirectional(LSTM(units=128, return_sequences=True), input_shape=(X_train_scaled.shape[1], X_train_scaled.shape[2])))
model.add(Dropout(0.2))
model.add(Bidirectional(LSTM(units=128, return_sequences=True)))
model.add(Dropout(0.2))
model.add(LSTM(units=64))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
# 訓練模型
model.fit(X_train_scaled, y_train_scaled, epochs=200, batch_size=32)
# 預測
y_train_pred = model.predict(X_train_scaled)
y_test_pred = model.predict(X_test_scaled)
# Debugging: Print shapes of key variables
print("X_train_scaled.shape:", X_train_scaled.shape)
print("y_train_scaled.shape:", y_train_scaled.shape)
print("y_train_pred.shape:", y_train_pred.shape)
print("X_test_scaled.shape:", X_test_scaled.shape)
print("y_test_scaled.shape:", y_test_scaled.shape)
print("y_test_pred.shape:", y_test_pred.shape)
# 將預測結果反轉回原始尺度
y_train_pred = target_scaler.inverse_transform(y_train_pred)
y_test_pred = target_scaler.inverse_transform(y_test_pred)
# 確保 y_train_pred 和 y_test_pred 是一維的
y_train_pred = y_train_pred.flatten()
y_test_pred = y_test_pred.flatten()
# 確保 dates 的長度與 target 一致
dates = data["^TWII"].loc["2021-01-01":].index
target = target.iloc[:len(dates)]
target_dates = dates[:len(target)]
# Debugging: Print shapes of key variables
print("train_dates.shape:", target_dates[:train_size].shape)
print("y_train_pred.shape:", y_train_pred.shape)
print("test_dates.shape:", target_dates[train_size:train_size + len(y_test_pred)].shape)
print("y_test_pred.shape:", y_test_pred.shape)
# Ensure y_train_pred and y_test_pred match the length of train and test dates
y_train_pred = y_train_pred[:len(target_dates[:train_size])]
y_test_pred = y_test_pred[:len(target_dates[train_size:train_size + len(y_test_pred)])]
# 繪圖
plt.figure(figsize=(14, 7))
# 繪製實際值
plt.plot(target_dates, target.values, color='blue', label='Actual TAIEX')
# 確保訓練集預測日期與預測值長度一致
train_dates = target_dates[:train_size]
plt.plot(train_dates, y_train_pred, color='orange', label='Training Prediction')
# 確保測試集預測日期與預測值長度一致
test_dates = target_dates[train_size:train_size + len(y_test_pred)]
plt.plot(test_dates, y_test_pred, color='green', label='Testing Prediction')
# 預測未來30天
future_steps = 30
future_predictions = []
if len(X_test_scaled) > 0:
last_test_data = X_test_scaled[-1].reshape(1, 1, -1)
for _ in range(future_steps):
next_pred = model.predict(last_test_data)
future_predictions.append(next_pred[0])
# 修正 DeprecationWarning 的問題,確保下一個預測點正確更新
last_test_data = np.roll(last_test_data, -1, axis=2)
last_test_data[0, 0, -1] = next_pred[0, 0]
future_predictions = target_scaler.inverse_transform(future_predictions)
# Make sure the future predictions start from the last point of actual data
if len(target.values) > 0:
future_predictions = np.insert(future_predictions, 0, target.values[-1])
# 生成未來日期索引
future_dates = pd.date_range(start=target_dates[-1], periods=future_steps + 1)
plt.plot(future_dates, future_predictions.flatten(), color='red', label='Future Prediction')
# 標識未來第 10、20、30 天的日期
for i, day in enumerate([10, 20, 30]):
plt.axvline(future_dates[day], color='purple', linestyle='--')
plt.text(future_dates[day], future_predictions[day], f'{future_dates[day].strftime("%m/%d")}: {future_predictions[day]:.2f}', color='purple')
plt.legend()
plt.title('TAIEX Prediction')
plt.xlabel('Days')
plt.ylabel('TAIEX Index')
# 標識日期
plt.gca().xaxis.set_major_formatter(plt.matplotlib.dates.DateFormatter('%Y/%m/%d'))
plt.gca().xaxis.set_major_locator(plt.matplotlib.dates.YearLocator())
plt.xticks(rotation=45)
plt.show()