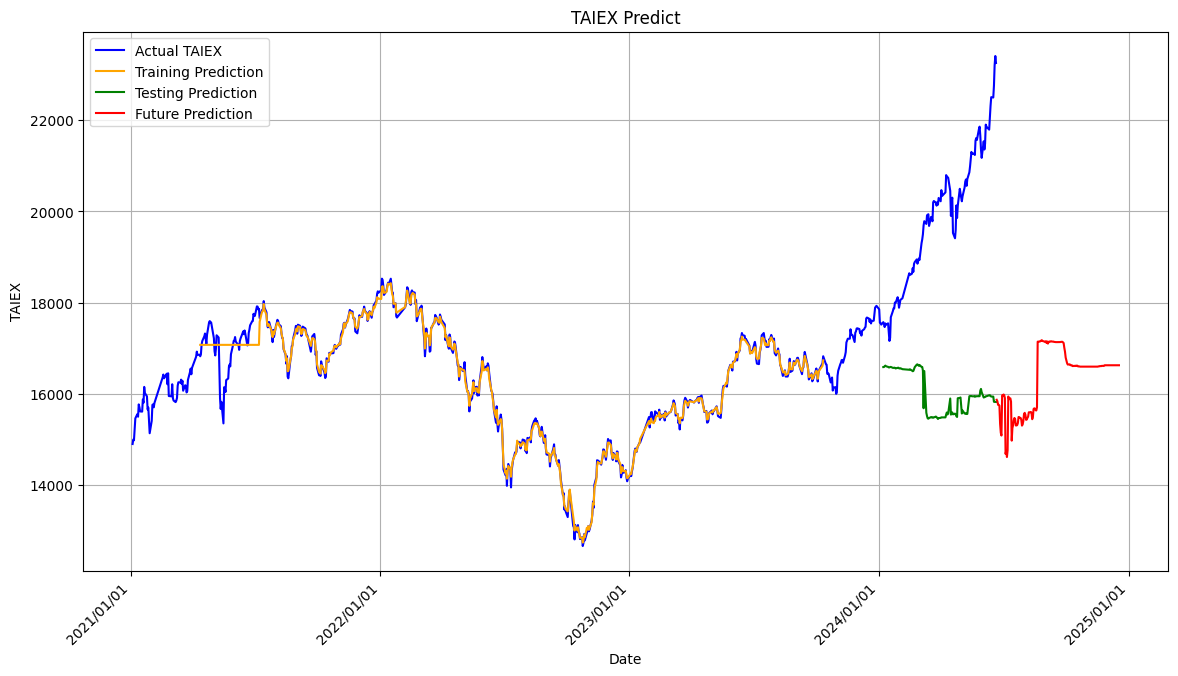
Random_Forest_TAIEX_POC_0628


dataset: MSCI top 30
from google.colab import drive
drive.mount('/content/drive')
!pip install yfinance scikit-learn matplotlib
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.ensemble import RandomForestRegressor
import matplotlib.dates as mdates
# 定義股票代碼和大盤指數
tickers = ["2330.TW", "2454.TW", "2317.TW", "2412.TW", "1303.TW", "2882.TW", "3008.TW", "2308.TW", "1402.TW",
"1216.TW", "2881.TW", "2891.TW", "2382.TW", "2409.TW", "1802.TW", "1101.TW", "3045.TW", "2324.TW",
"2105.TW", "2880.TW", "2887.TW", "2885.TW", "4904.TW", "2603.TW", "2884.TW", "2886.TW", "2357.TW",
"2344.TW", "4938.TW", "2888.TW", "^TWII"]
# 下載股票數據
data = yf.download(tickers, start="2021-01-01", end="2024-06-24")
# 使用前向填充處理缺失值
data = data.ffill()
# 提取調整後收盤價
adj_close = data['Adj Close']
# 計算日變動率
daily_change = adj_close.pct_change()
# 計算 Beta 值
def calculate_beta(stock_returns, market_returns, window):
cov_matrix = stock_returns.rolling(window).cov(market_returns)
var_market = market_returns.rolling(window).var()
beta = cov_matrix.div(var_market, axis=0)
return beta
# 市場回報率
market_returns = daily_change["^TWII"]
# 計算 Beta_120
beta_120 = daily_change.apply(lambda x: calculate_beta(x, market_returns, 120))
# 整合所有特徵變數
features = pd.DataFrame()
for ticker in tickers[:-1]: # 除去 "^TWII"
features[ticker] = beta_120[ticker]
# 使用前向填充處理缺失值
features = features.ffill()
# 確保没有 NaN 值
features = features.fillna(0)
# 設置目標變數
target = adj_close["^TWII"]
# 數據標準化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_features = scaler.fit_transform(features)
scaled_target = scaler.fit_transform(target.values.reshape(-1, 1))
# 確認没有出現nan值
print("Checking for NaN values in scaled_features and scaled_target:")
print(np.isnan(scaled_features).sum())
print(np.isnan(scaled_target).sum())
# 創建時間序列數據
def create_dataset(X, y, time_step=1):
Xs, ys = [], []
for i in range(len(X)-time_step):
Xs.append(X[i:(i+time_step), :])
ys.append(y[i + time_step])
return np.array(Xs), np.array(ys)
# 定義時間步長
time_step = 60
# 創建訓練和測試數據集
train_size = int(len(scaled_features) * 0.8)
X_train, y_train = create_dataset(scaled_features[:train_size], scaled_target[:train_size], time_step)
X_test, y_test = create_dataset(scaled_features[train_size:], scaled_target[train_size:], time_step)
# 將數據調整為2D以適應隨機森林
X_train_2d = X_train.reshape(X_train.shape[0], -1)
X_test_2d = X_test.reshape(X_test.shape[0], -1)
# 建立隨機森林模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
# 訓練模型
model.fit(X_train_2d, y_train)
# 預測
train_predict = model.predict(X_train_2d)
test_predict = model.predict(X_test_2d)
# 反標準化
train_predict = scaler.inverse_transform(train_predict.reshape(-1, 1))
test_predict = scaler.inverse_transform(test_predict.reshape(-1, 1))
y_train = scaler.inverse_transform(y_train.reshape(-1, 1))
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
# 調整索引和預測值的長度一致
train_predict_index = target.index[time_step:time_step + len(train_predict)]
test_predict_index = target.index[train_size + time_step:train_size + time_step + len(test_predict)]
# 繪製整個數據集的走勢圖
plt.figure(figsize=(14, 7))
plt.plot(target.index, target, color='blue', label='Actual TAIEX')
plt.plot(train_predict_index, train_predict, color='orange', label='Training Prediction')
plt.plot(test_predict_index, test_predict, color='green', label='Testing Prediction')
# 生成未來 180 天的預測
future_steps = 180
future_features = scaled_features[-time_step:]
future_predict = []
for i in range(future_steps):
future_features_2d = future_features.reshape(1, -1)
pred = model.predict(future_features_2d)
print(f"Step {i} - Prediction: {pred}") # 打印每一步的预测值
if np.isnan(pred).any(): # 檢查预测值是否為 nan
print(f"Step {i} - Prediction contains nan values")
break
future_predict.append(pred[0])
pred = np.repeat(pred, future_features.shape[1]).reshape(1, future_features.shape[1]) # 将pred调整为与future_features匹配的形狀
future_features = np.append(future_features[1:, :], pred, axis=0)
future_predict = np.array(future_predict).reshape(-1, 1)
print(f"future_predict shape: {future_predict.shape}") # 確認 future_predict 形狀
print(f"future_predict data: {future_predict[:5]}") # 打印前5个预测数据以供检查
if future_predict.size > 0:
future_predict = scaler.inverse_transform(future_predict)
future_dates = pd.date_range(start=target.index[-1], periods=future_steps+1, inclusive='right')
print(f"future_dates: {future_dates}") # 確認 future_dates 的生成
plt.plot(future_dates, future_predict, color='red', label='Future Prediction')
# 設置 X 軸日期格式
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y/%m/%d'))
plt.gca().xaxis.set_major_locator(mdates.YearLocator())
plt.xticks(rotation=45, ha='right')
plt.xlabel('Date')
plt.ylabel('TAIEX')
plt.title('TAIEX Predict')
plt.legend()
plt.grid(True)
plt.show()