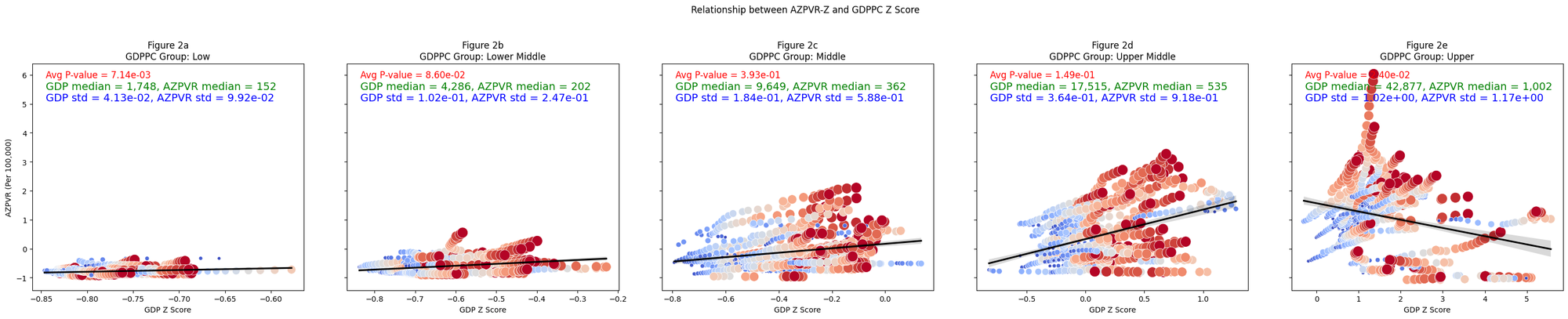
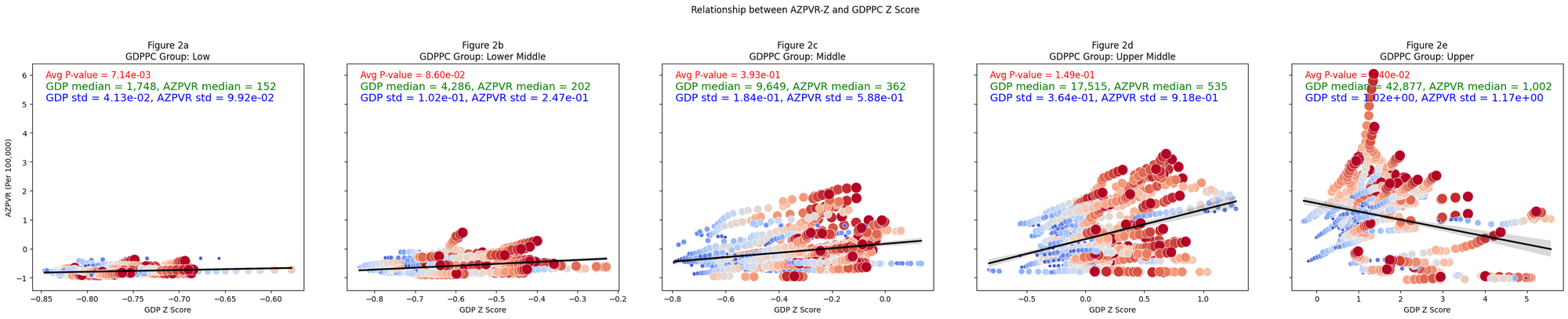
Relationship between AZPVR and GDPPC Z Score

Source Code
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
from google.colab import drive
# Suppress warnings
import warnings
warnings.simplefilter('ignore', np.RankWarning)
# Mount Google Drive
drive.mount('/content/drive')
# Load the data
file_path = '/content/drive/My Drive/dataset/az_0704.csv'
data = pd.read_csv(file_path)
# Define GDP group names
gdp_group_names = {0: 'Low', 1: 'Lower Middle', 2: 'Middle', 3: 'Upper Middle', 4: 'Upper'}
figure_labels = ['Figure 2a', 'Figure 2b', 'Figure 2c', 'Figure 2d', 'Figure 2e']
# Normalize the GDP and AZ100K columns
data['GDP_zscore'] = (data['gdppp2017'] - data['gdppp2017'].mean()) / data['gdppp2017'].std()
data['AZ100K_zscore'] = (data['az100k'] - data['az100k'].mean()) / data['az100k'].std()
# Create scatter plots with regression lines for each GDP group
fig, axes = plt.subplots(1, 5, figsize=(30, 6), sharey=True)
fig.suptitle('Relationship between AZPVR-Z and GDPPC Z Score')
avg_p_values = []
for idx, gdp_group in enumerate(gdp_group_names.keys()):
subset = data[data['gdpg1'] == gdp_group]
p_values = []
if len(subset) > 1 and subset['GDP_zscore'].std() > 0 and subset['AZ100K_zscore'].std() > 0:
years = subset['year'].unique()
for year in years:
year_subset = subset[subset['year'] == year]
if len(year_subset) > 1:
slope, intercept, r_value, p_value, std_err = stats.linregress(year_subset['GDP_zscore'], year_subset['AZ100K_zscore'])
p_values.append(p_value)
avg_p_value = np.nanmean(p_values) if p_values else np.nan
avg_p_values.append(avg_p_value)
# Calculate medians
gdp_median = subset['gdppp2017'].median()
az100k_median = subset['az100k'].median()
# Create the scatter plot
ax = axes[idx]
sns.scatterplot(ax=ax, x='GDP_zscore', y='AZ100K_zscore', hue='year', size='year', sizes=(20, 200), data=subset, palette='coolwarm', legend=False)
sns.regplot(ax=ax, x='GDP_zscore', y='AZ100K_zscore', data=subset, scatter=False, color='black')
ax.set_title(f'{figure_labels[idx]}\nGDPPC Group: {gdp_group_names[gdp_group]}')
ax.set_xlabel('GDP Z Score')
if idx == 0:
ax.set_ylabel('AZPVR (Per 100,000)')
if not np.isnan(avg_p_value):
ax.text(0.05, 0.95, f'Avg P-value = {avg_p_value:.2e}', ha='left', va='center', transform=ax.transAxes, color='red', fontsize=12)
else:
ax.text(0.05, 0.95, 'Avg P-value = NaN (insufficient data or low variance)', ha='left', va='center', transform=ax.transAxes, color='red', fontsize=14)
ax.text(0.05, 0.85, f'GDP std = {subset["GDP_zscore"].std():.2e}, AZPVR std = {subset["AZ100K_zscore"].std():.2e}', ha='left', va='center', transform=ax.transAxes, color='blue', fontsize=14)
ax.text(0.05, 0.90, f'GDP median = {gdp_median:,.0f}, AZPVR median = {az100k_median:,.0f}', ha='left', va='center', transform=ax.transAxes, color='green', fontsize=14)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
# Print overall average P-value
overall_avg_p_value = np.nanmean(avg_p_values)
print(f'Overall Average P-value: {overall_avg_p_value:.2e}')