1107_6.1 簡單的實作


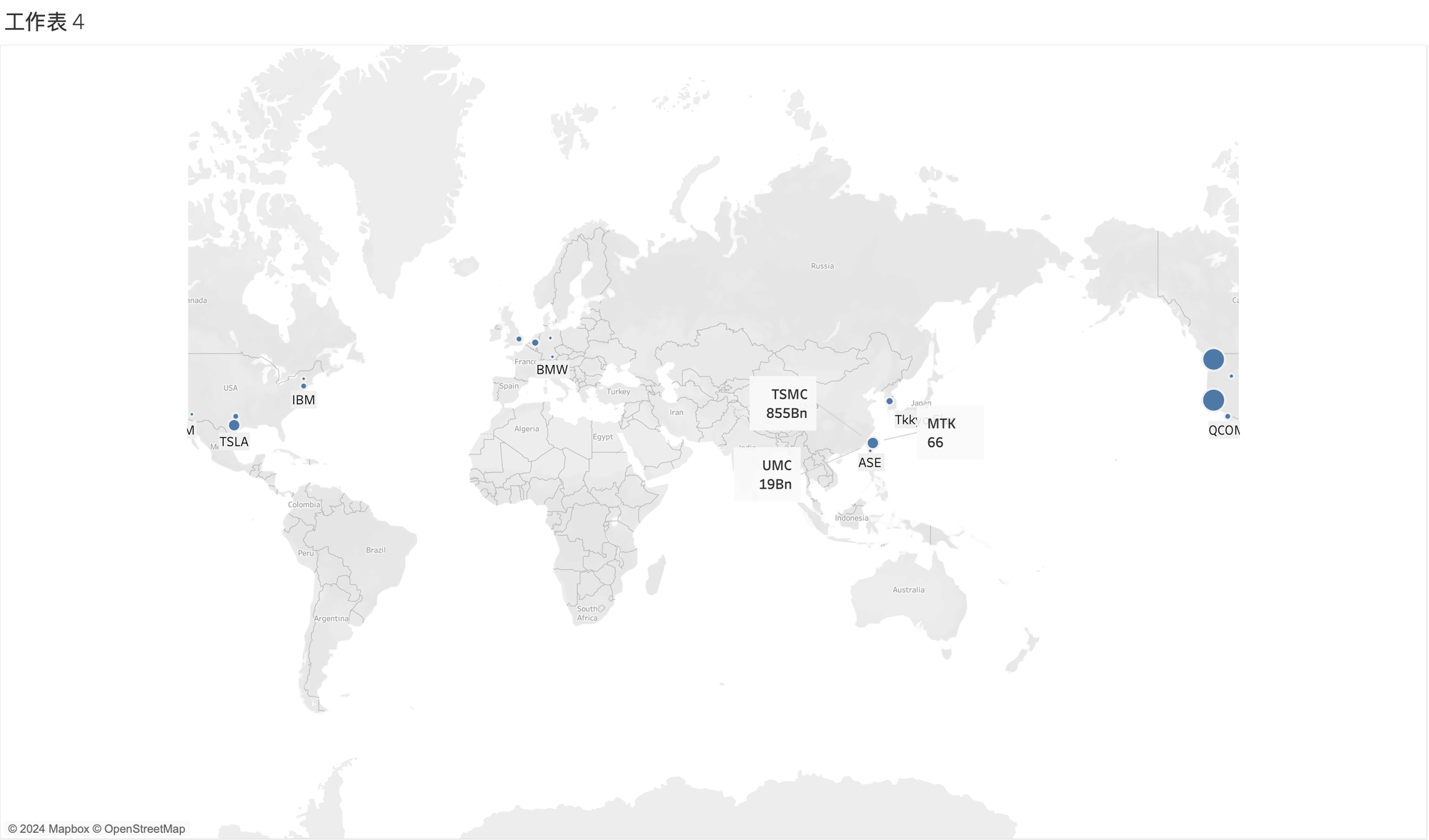
Dataset
TKU_1105_STU - Google Drive

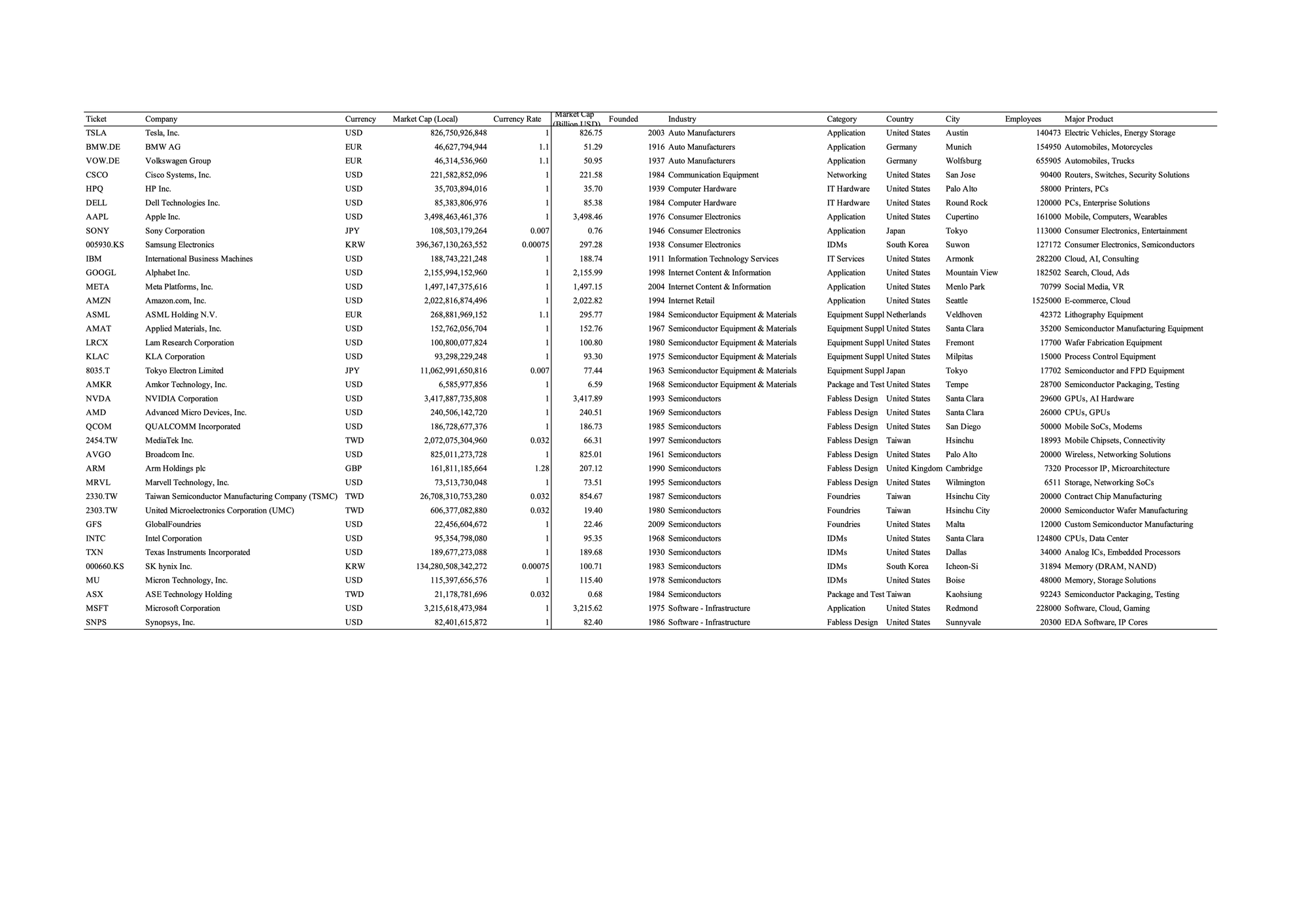
Description Statistic
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
# 讀取 CSV 文件
file_path = '/content/drive/My Drive/TKU_Semi_36/semi36_Panel_data_with_Company_Code(TKU).csv'
df = pd.read_csv(file_path)
# 假設 df 是包含公司資訊的 DataFrame,並已經有以下欄位:
# ['Ticket', 'Company', 'Currency', 'Market Cap (Local)', 'Currency Rate', 'Market Cap (Billion USD)', 'Founded', 'Industry', 'Category', 'Country', 'City', 'Employees', 'Major Product']
# 確保 'Founded'、'Market Cap (Billion USD)' 和 'Employees' 欄位數值為浮點型,方便進行統計分析
df['Founded'] = pd.to_numeric(df['Founded'], errors='coerce')
df['Market Cap (Billion USD)'] = pd.to_numeric(df['Market Cap (Billion USD)'], errors='coerce')
df['Employees'] = pd.to_numeric(df['Employees'], errors='coerce')
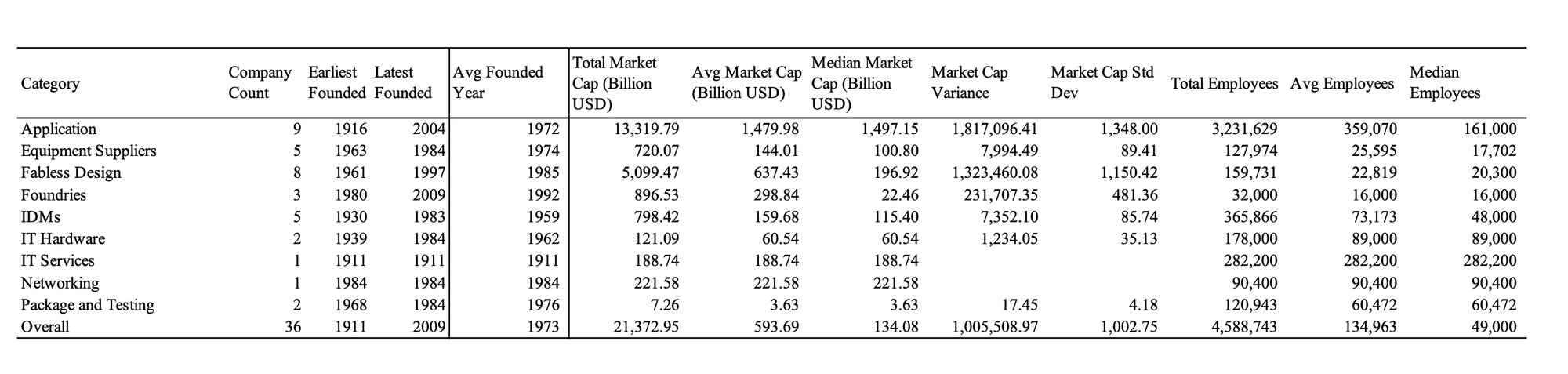
# 定義一個函數來計算每個 Category 的敘述統計
def descriptive_statistics_by_category(df):
result = []
for category, group in df.groupby('Category'):
# 公司數量
company_count = group['Company'].nunique()
# 創立年份的統計
earliest_founded = group['Founded'].min()
latest_founded = group['Founded'].max()
avg_founded_year = group['Founded'].mean()
# 市值的統計
total_market_cap = group['Market Cap (Billion USD)'].sum()
avg_market_cap = group['Market Cap (Billion USD)'].mean()
median_market_cap = group['Market Cap (Billion USD)'].median()
market_cap_variance = group['Market Cap (Billion USD)'].var()
market_cap_std_dev = group['Market Cap (Billion USD)'].std()
# 員工數的統計
total_employees = group['Employees'].sum()
avg_employees = group['Employees'].mean()
median_employees = group['Employees'].median()
# 將結果添加到列表
result.append({
"Category": category,
"Company Count": company_count,
"Earliest Founded": earliest_founded,
"Latest Founded": latest_founded,
"Avg Founded Year": avg_founded_year,
"Total Market Cap (Billion USD)": total_market_cap,
"Avg Market Cap (Billion USD)": avg_market_cap,
"Median Market Cap (Billion USD)": median_market_cap,
"Market Cap Variance": market_cap_variance,
"Market Cap Std Dev": market_cap_std_dev,
"Total Employees": total_employees,
"Avg Employees": avg_employees,
"Median Employees": median_employees
})
# 添加 Overall 行,統計整體數據
overall = {
"Category": "Overall",
"Company Count": df['Company'].nunique(),
"Earliest Founded": df['Founded'].min(),
"Latest Founded": df['Founded'].max(),
"Avg Founded Year": df['Founded'].mean(),
"Total Market Cap (Billion USD)": df['Market Cap (Billion USD)'].sum(),
"Avg Market Cap (Billion USD)": df['Market Cap (Billion USD)'].mean(),
"Median Market Cap (Billion USD)": df['Market Cap (Billion USD)'].median(),
"Market Cap Variance": df['Market Cap (Billion USD)'].var(),
"Market Cap Std Dev": df['Market Cap (Billion USD)'].std(),
"Total Employees": df['Employees'].sum(),
"Avg Employees": df['Employees'].mean(),
"Median Employees": df['Employees'].median()
}
# 將 Overall 結果添加到結果列表
result.append(overall)
# 將結果轉換為 DataFrame 並返回
return pd.DataFrame(result)
# 使用函數生成各 Category 的敘述統計表
category_stats_df = descriptive_statistics_by_category(df)
# 保存結果到 CSV 文件
output_file_path = '/content/drive/My Drive/TKU_Semi_36/Category_Descriptive_Statistics_with_Overall.csv'
category_stats_df.to_csv(output_file_path, index=False)
print(f"數據已保存至 {output_file_path}")
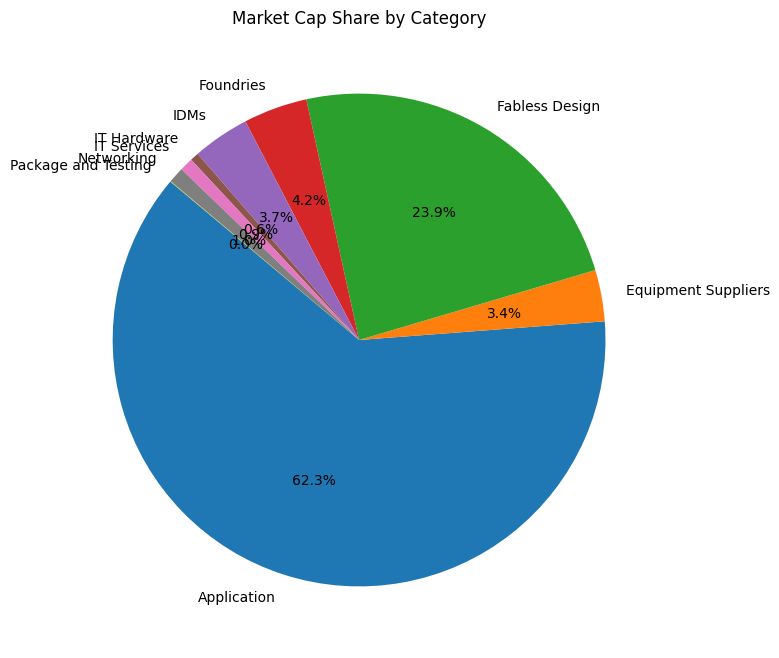
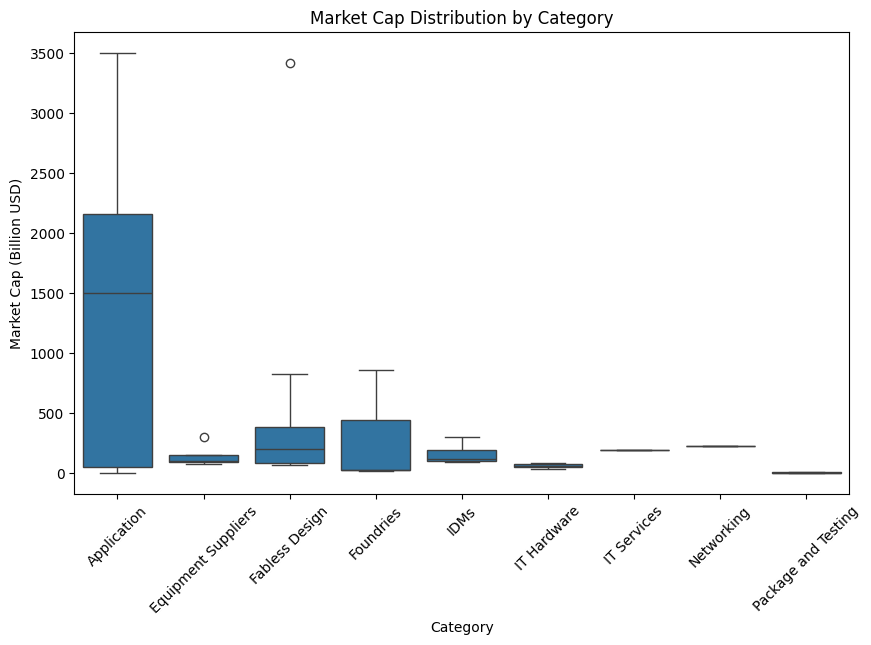
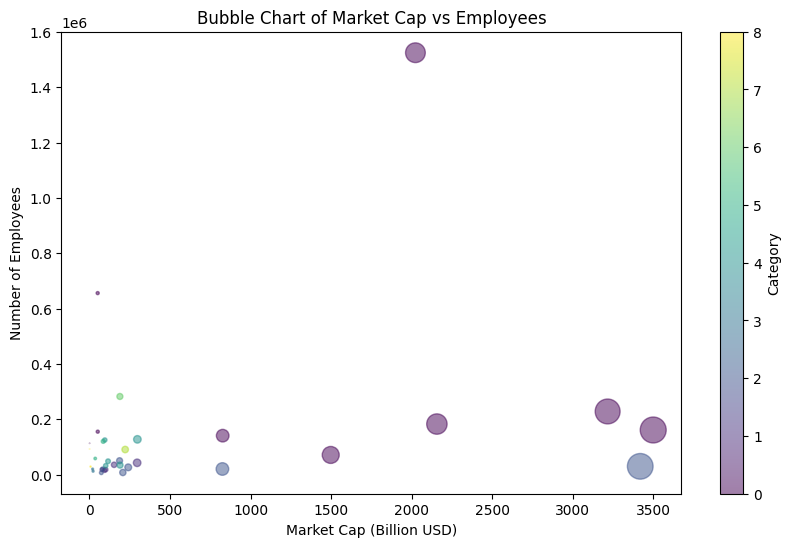
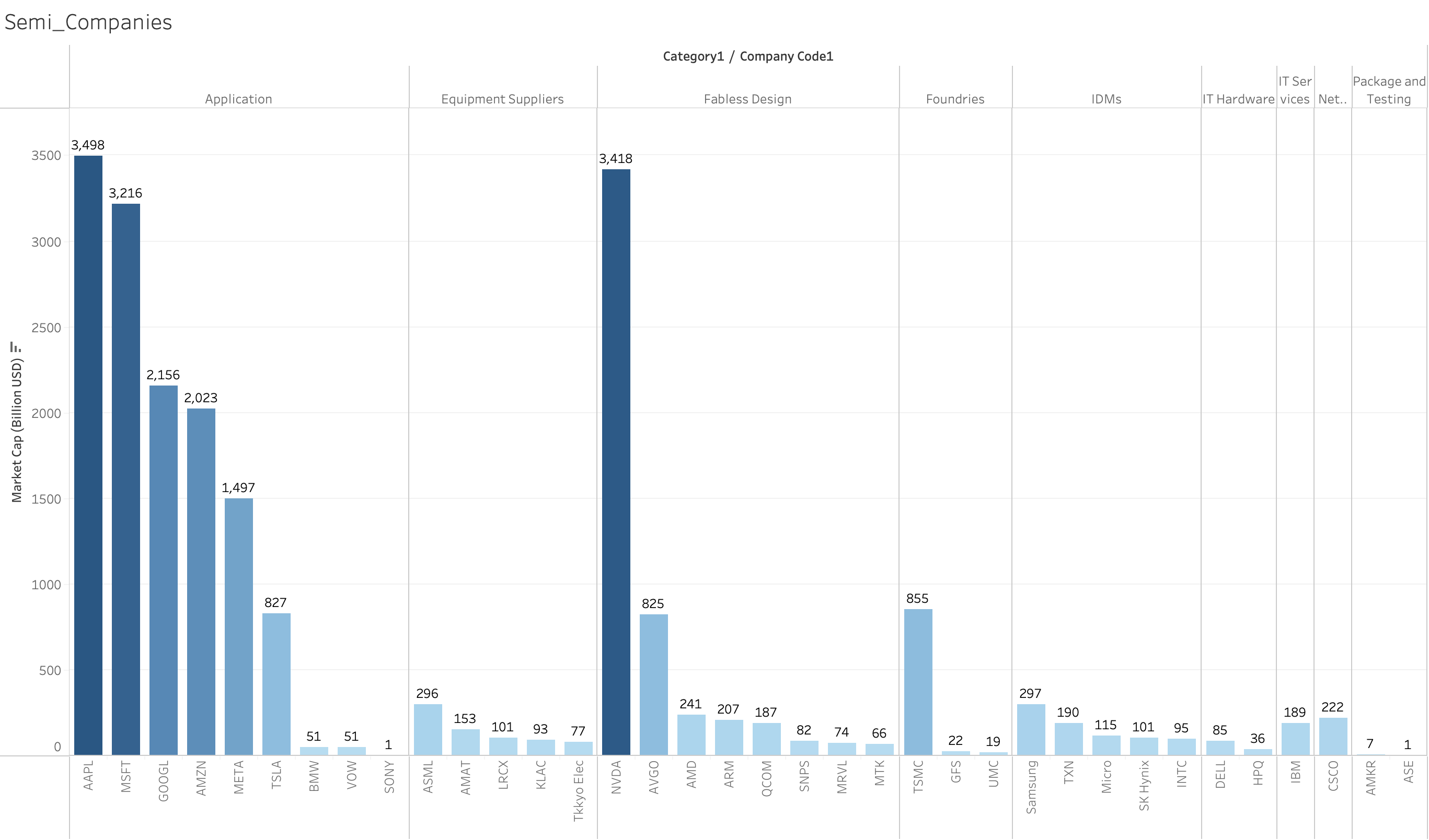
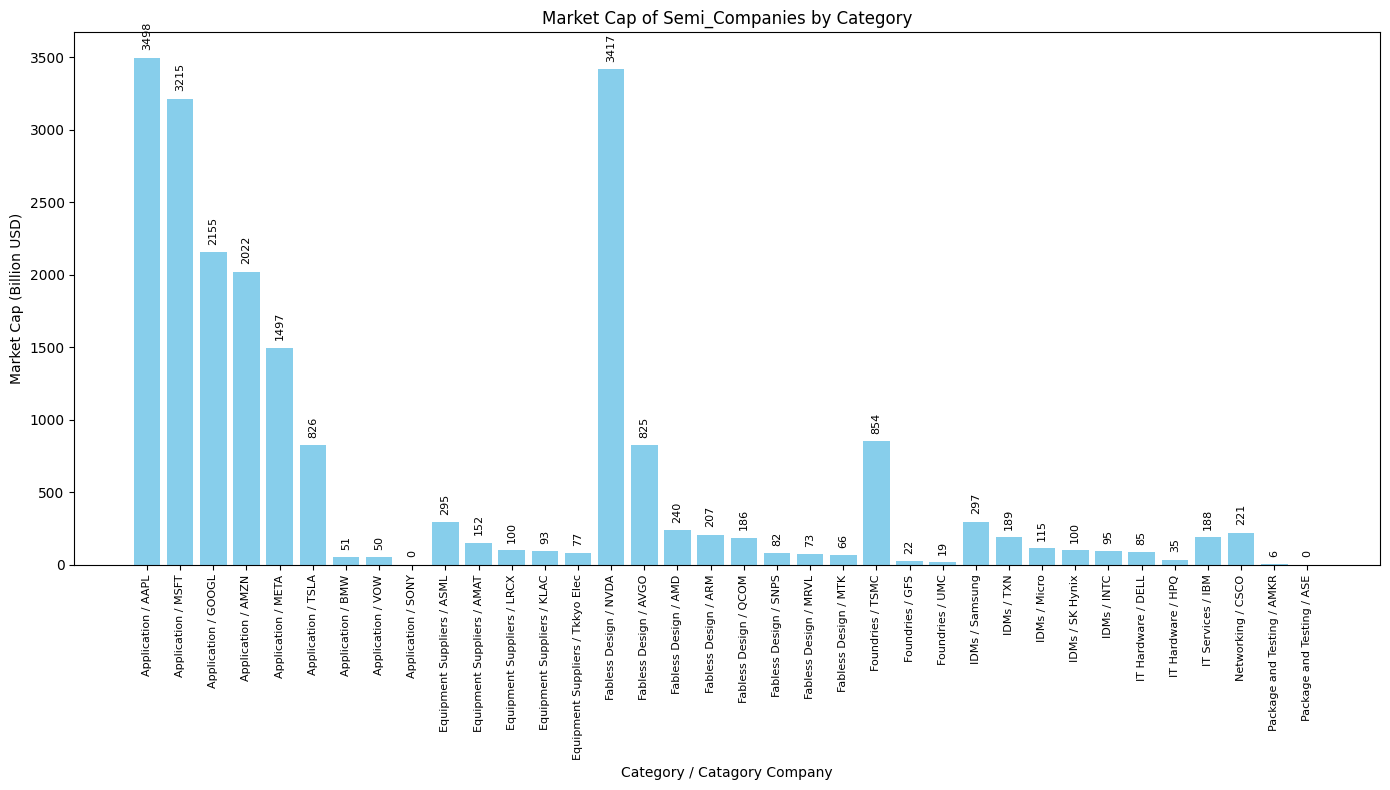
Bar chart
import pandas as pd
import matplotlib.pyplot as plt
# 讀取 CSV 文件
file_path = '/content/drive/My Drive/TKU_Semi_36/semi36_Panel_data_with_Company_Code.csv'
df = pd.read_csv(file_path)
# 將 Category 和 Company 名稱組合,便於作圖標籤
df['Category_Company'] = df['Category'] + " / " + df['Company Code']
# 排序數據,以便按市值從大到小顯示
df = df.sort_values(by=['Category', 'Market Cap (Billion USD)'], ascending=[True, False])
# 設定圖形尺寸
plt.figure(figsize=(14, 8))
# 繪製長條圖
plt.bar(df['Category_Company'], df['Market Cap (Billion USD)'], color='skyblue')
# 加上數值標籤
for i, value in enumerate(df['Market Cap (Billion USD)']):
plt.text(i, value + 50, f'{int(value)}', ha='center', va='bottom', fontsize=8, rotation=90)
# 添加標題和標籤
plt.title("Market Cap of Semi_Companies by Category")
plt.xlabel("Category / Catagory Company")
plt.ylabel("Market Cap (Billion USD)")
# 調整 X 軸標籤角度
plt.xticks(rotation=90, ha='center', fontsize=8)
# 展示圖形
plt.tight_layout()
plt.show()