**TAIEX.s44_Linear Regression.

import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from google.colab import drive
import warnings
# Mount Google Drive
drive.mount('/content/drive', force_remount=True)
# Check file path
file_path = '/content/drive/My Drive/MSCI_Taiwan_30_data_with_OBV.csv'
if os.path.exists(file_path):
print("File exists")
data = pd.read_csv(file_path)
else:
print("File does not exist")
# Ensure the date column is converted to datetime type
data['Date'] = pd.to_datetime(data['Date'])
# Print column names to check if 'Close_TAIEX' column exists
print(data.columns)
# Feature Engineering
data['MA7'] = data['Close'].rolling(window=7).mean()
data['MA21'] = data['Close'].rolling(window=21).mean()
def compute_rsi(data, window=14):
delta = data['Close'].diff(1)
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
rsi = 100 - (100 / (1 + rs))
return rsi
data['RSI14'] = compute_rsi(data)
def compute_macd(data, fast=12, slow=26, signal=9):
exp1 = data['Close'].ewm(span=fast, adjust=False).mean()
exp2 = data['Close'].ewm(span=slow, adjust=False).mean()
macd = exp1 - exp2
signal_line = macd.ewm(span=signal, adjust=False).mean()
return macd, signal_line
data['MACD Line'], data['MACD Signal'] = compute_macd(data)
# Prepare data
if 'Close_TAIEX' in data.columns:
data = data.dropna(subset=['Close_TAIEX'])
series = data[['Date', 'Close_TAIEX']]
series.set_index('Date', inplace=True)
else:
print("The data does not contain 'Close_TAIEX' column")
raise KeyError("The data does not contain 'Close_TAIEX' column")
# Selecting Features (excluding non-numeric columns)
numeric_data = data.select_dtypes(include=[np.number])
X = numeric_data.drop(['Close_TAIEX'], axis=1).fillna(0)
y = numeric_data['Close_TAIEX']
bestfeatures = SelectKBest(score_func=f_regression, k=6)
fit = bestfeatures.fit(X, y)
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(X.columns)
# Concatenate dataframes for better visualization
featureScores = pd.concat([dfcolumns, dfscores], axis=1)
featureScores.columns = ['Features', 'Score']
print(featureScores.nlargest(6, 'Score'))
# Get the top 6 features
selected_features = featureScores.nlargest(6, 'Score')['Features'].values
print("Selected features:", selected_features)
# Split data into train and test sets
X_selected = data[selected_features].fillna(0)
X_train, X_test, y_train, y_test = train_test_split(X_selected, y, test_size=0.2, random_state=42, shuffle=False)
# Train Linear Regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Calculate errors
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
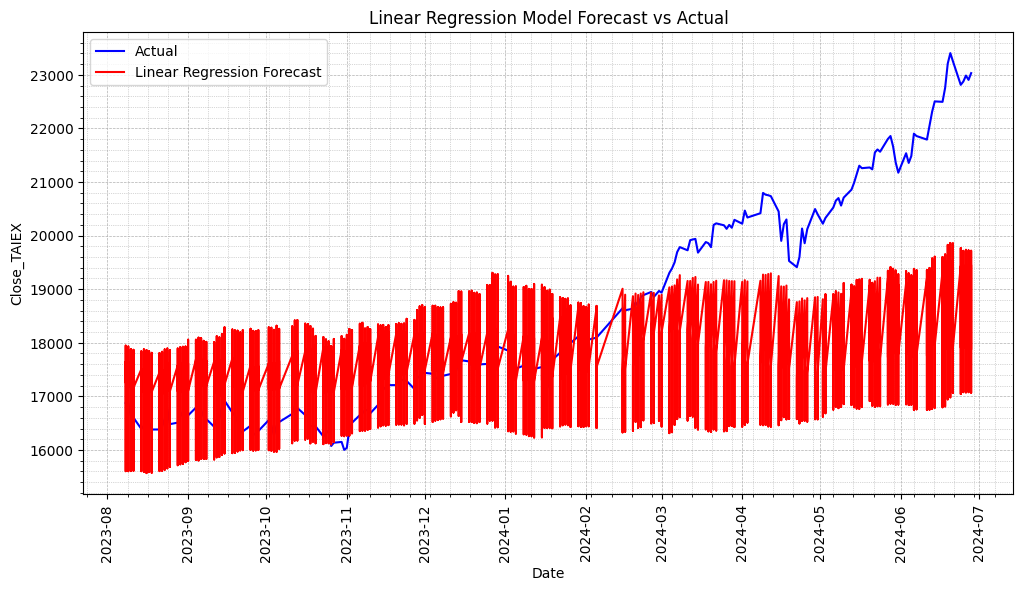
# Plot actual values and predictions
plt.figure(figsize=(12, 6))
# Plot actual values
plt.plot(series.index[-len(y_test):], y_test, label='Actual', color='blue')
# Plot predictions
plt.plot(series.index[-len(y_test):], y_pred, label='Linear Regression Forecast', color='red')
plt.title('Linear Regression Model Forecast vs Actual')
plt.xlabel('Date')
plt.ylabel('Close_TAIEX')
plt.legend()
# Set date format and rotate x-axis labels
plt.gca().xaxis.set_major_locator(mdates.MonthLocator())
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
plt.gca().tick_params(axis='x', rotation=90)
# Add grid
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.minorticks_on()
plt.grid(True, which='minor', linestyle=':', linewidth=0.5)
# Show plot
plt.show()
# Print MSE and MAE
print(f'Linear Regression Model Mean Squared Error (MSE): {mse}')
print(f'Linear Regression Model Mean Absolute Error (MAE): {mae}')
# Print all selected features for reference
print("Selected features used in the model:", selected_features)
Mounted at /content/drive
File exists
Index(['Date', 'ST_Code', 'ST_Name', 'Open', 'High', 'Low', 'Close',
'Adj_Close', 'Volume', 'MA7', 'MA21', 'MA50', 'MA100', 'Middle Band',
'Upper Band', 'Lower Band', 'Band Width', 'Aroon Up', 'Aroon Down',
'CCI20', 'CMO14', 'MACD Line', 'Signal Line', 'MACD Histogram', 'RSI7',
'RSI14', 'RSI21', '%K', '%D', 'WILLR14', 'Market Return',
'Stock Return', 'Beta_60', 'Beta_120', 'Close_TAIEX', 'OBV'],
dtype='object')
Features Score
31 OBV 29841.246650
23 RSI21 2449.256989
30 Beta_120 1751.016314
7 MA21 886.321722
14 Aroon Up 628.996394
21 RSI7 442.461645
Selected features: ['OBV' 'RSI21' 'Beta_120' 'MA21' 'Aroon Up' 'RSI7']
Linear Regression Model Mean Squared Error (MSE): 3723976.170236745
Linear Regression Model Mean Absolute Error (MAE): 1473.1620038283527
Selected features used in the model: ['OBV' 'RSI21' 'Beta_120' 'MA21' 'Aroon Up' 'RSI7']
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from scipy.stats import pearsonr
from google.colab import drive
# Mount Google Drive
drive.mount('/content/drive', force_remount=True)
# Check file path
file_path = '/content/drive/My Drive/MSCI_Taiwan_30_data_with_OBV.csv'
if os.path.exists(file_path):
print("File exists")
data = pd.read_csv(file_path)
else:
print("File does not exist")
# Ensure the date column is converted to datetime type
data['Date'] = pd.to_datetime(data['Date'])
# Print column names to check if 'Close_TAIEX' column exists
print(data.columns)
# Feature Engineering using Adj_Close for moving averages
data['MA7'] = data['Adj_Close'].rolling(window=7).mean()
data['MA21'] = data['Adj_Close'].rolling(window=21).mean()
def compute_rsi(data, window=14):
delta = data['Adj_Close'].diff(1)
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
rsi = 100 - (100 / (1 + rs))
return rsi
data['RSI14'] = compute_rsi(data)
def compute_macd(data, fast=12, slow=26, signal=9):
exp1 = data['Adj_Close'].ewm(span=fast, adjust=False).mean()
exp2 = data['Adj_Close'].ewm(span=slow, adjust=False).mean()
macd = exp1 - exp2
signal_line = macd.ewm(span=signal, adjust=False).mean()
return macd, signal_line
data['MACD Line'], data['MACD Signal'] = compute_macd(data)
# Prepare data
if 'Close_TAIEX' in data.columns:
data = data.dropna(subset=['Close_TAIEX'])
series = data[['Date', 'Close_TAIEX']]
series.set_index('Date', inplace=True)
else:
print("The data does not contain 'Close_TAIEX' column")
raise KeyError("The data does not contain 'Close_TAIEX' column")
# Selecting Features (excluding non-numeric columns)
numeric_data = data.select_dtypes(include=[np.number])
X = numeric_data.drop(['Close_TAIEX'], axis=1).fillna(0)
y = numeric_data['Close_TAIEX']
# Feature Selection using Pearson correlation
selected_features = []
for column in X.columns:
corr, p_value = pearsonr(X[column], y)
if abs(corr) > 0.3 and p_value < 0.05:
selected_features.append(column)
print("Selected features:", selected_features)
# Split data into train and test sets
X_selected = data[selected_features].fillna(0)
X_train, X_test, y_train, y_test = train_test_split(X_selected, y, test_size=0.2, random_state=42, shuffle=False)
# Train Linear Regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Calculate errors
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
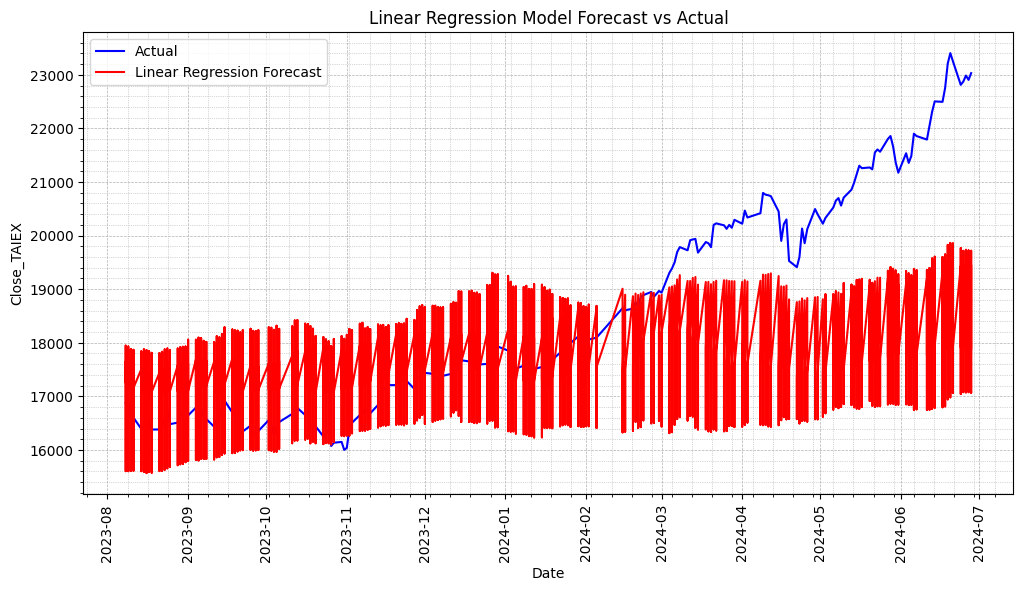
# Plot actual values and predictions
plt.figure(figsize=(12, 6))
# Plot actual values
plt.plot(series.index[-len(y_test):], y_test, label='Actual', color='blue')
# Plot predictions
plt.plot(series.index[-len(y_test):], y_pred, label='Linear Regression Forecast', color='red')
plt.title('Linear Regression Model Forecast vs Actual')
plt.xlabel('Date')
plt.ylabel('Close_TAIEX')
plt.legend()
# Set date format and rotate x-axis labels
plt.gca().xaxis.set_major_locator(mdates.MonthLocator())
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
plt.gca().tick_params(axis='x', rotation=90)
# Add grid
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.minorticks_on()
plt.grid(True, which='minor', linestyle=':', linewidth=0.5)
# Show plot
plt.show()
# Print MSE and MAE
print(f'Linear Regression Model Mean Squared Error (MSE): {mse}')
print(f'Linear Regression Model Mean Absolute Error (MAE): {mae}')
# Print all selected features for reference
print("Selected features used in the model:", selected_features)
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from scipy.stats import pearsonr
from google.colab import drive
# Mount Google Drive
drive.mount('/content/drive', force_remount=True)
# Check file path
file_path = '/content/drive/My Drive/MSCI_Taiwan_30_data_with_OBV.csv'
if os.path.exists(file_path):
print("File exists")
data = pd.read_csv(file_path)
else:
print("File does not exist")
# Ensure the date column is converted to datetime type
data['Date'] = pd.to_datetime(data['Date'])
# Print column names to check if 'Close_TAIEX' column exists
print(data.columns)
# Feature Engineering using Adj_Close for moving averages
data['MA7'] = data['Adj_Close'].rolling(window=7).mean()
data['MA21'] = data['Adj_Close'].rolling(window=21).mean()
def compute_rsi(data, window=14):
delta = data['Adj_Close'].diff(1)
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
rsi = 100 - (100 / (1 + rs))
return rsi
data['RSI14'] = compute_rsi(data)
def compute_macd(data, fast=12, slow=26, signal=9):
exp1 = data['Adj_Close'].ewm(span=fast, adjust=False).mean()
exp2 = data['Adj_Close'].ewm(span=slow, adjust=False).mean()
macd = exp1 - exp2
signal_line = macd.ewm(span=signal, adjust=False).mean()
return macd, signal_line
data['MACD Line'], data['MACD Signal'] = compute_macd(data)
# Prepare data
if 'Close_TAIEX' in data.columns:
data = data.dropna(subset=['Close_TAIEX'])
series = data[['Date', 'Close_TAIEX']]
series.set_index('Date', inplace=True)
else:
print("The data does not contain 'Close_TAIEX' column")
raise KeyError("The data does not contain 'Close_TAIEX' column")
# Selecting Features (excluding non-numeric columns)
numeric_data = data.select_dtypes(include=[np.number])
X = numeric_data.drop(['Close_TAIEX'], axis=1).fillna(0)
y = numeric_data['Close_TAIEX']
# Feature Selection using Pearson correlation
selected_features = []
for column in X.columns:
corr, p_value = pearsonr(X[column], y)
if abs(corr) > 0.3 and p_value < 0.05:
selected_features.append(column)
print("Selected features:", selected_features)
# Split data into train and test sets
X_selected = data[selected_features].fillna(0)
X_train, X_test, y_train, y_test = train_test_split(X_selected, y, test_size=0.2, random_state=42, shuffle=False)
# Train Linear Regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Calculate errors
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
# Plot actual values and predictions
plt.figure(figsize=(12, 6))
# Plot actual values
plt.plot(series.index[-len(y_test):], y_test, label='Actual', color='blue')
# Plot predictions
plt.plot(series.index[-len(y_test):], y_pred, label='Linear Regression Forecast', color='red')
plt.title('Linear Regression Model Forecast vs Actual')
plt.xlabel('Date')
plt.ylabel('Close_TAIEX')
plt.legend()
# Set date format and rotate x-axis labels
plt.gca().xaxis.set_major_locator(mdates.MonthLocator())
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
plt.gca().tick_params(axis='x', rotation=90)
# Add grid
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.minorticks_on()
plt.grid(True, which='minor', linestyle=':', linewidth=0.5)
# Show plot
plt.show()
# Print MSE and MAE
print(f'Linear Regression Model Mean Squared Error (MSE): {mse}')
print(f'Linear Regression Model Mean Absolute Error (MAE): {mae}')
# Print all selected features for reference
print("Selected features used in the model:", selected_features)
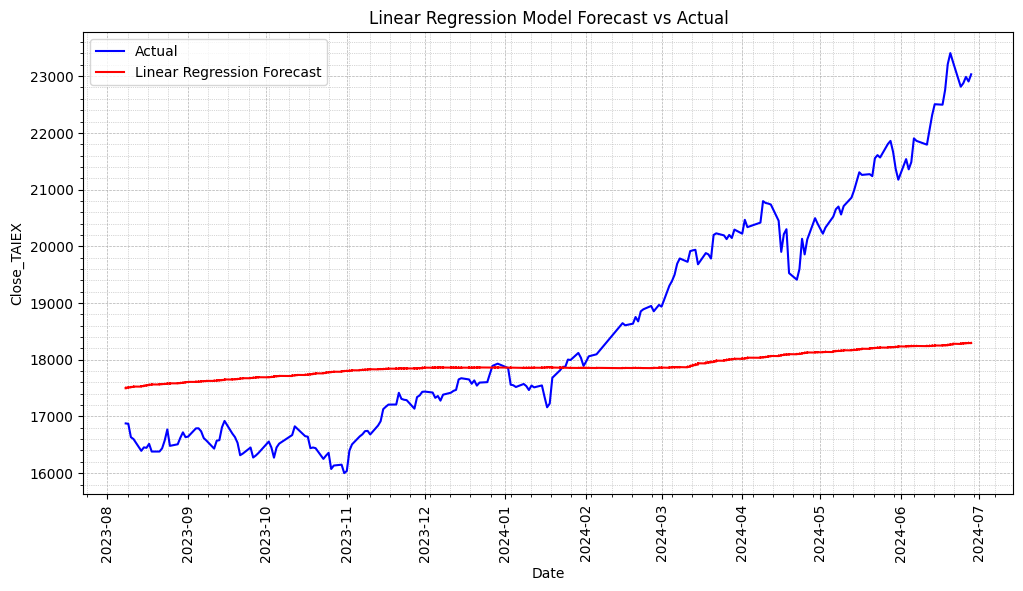
Linear Regression Model Mean Squared Error (MSE): 3662405.2159896246
Linear Regression Model Mean Absolute Error (MAE): 1512.8870311948879
Selected features used in the model: Index(['OBV', 'Signal Line', 'Market Return', 'MACD Histogram', 'Aroon Down', 'CCI20'],dtype='object')