import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
from statsmodels.tsa.arima.model import ARIMA
from sklearn.linear_model import LinearRegression
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from xgboost import XGBRegressor
from sklearn.decomposition import PCA
from sklearn.metrics import mean_squared_error, mean_absolute_error
from google.colab import drive
from sklearn.neighbors import KNeighborsRegressor
# Mount Google Drive
drive.mount('/content/drive', force_remount=True)
# Check file path
file_path = '/content/drive/My Drive/MSCI_Taiwan_30_data_with_OBV.csv'
if os.path.exists(file_path):
print("File exists")
data = pd.read_csv(file_path)
else:
print("File does not exist")
# Print column names to check for 'Close' column
print(data.columns)
# Ensure 'Date' column is in datetime format
data['Date'] = pd.to_datetime(data['Date'])
# Fill missing values
numeric_columns = data.select_dtypes(include=[np.number]).columns
data[numeric_columns] = data[numeric_columns].fillna(data[numeric_columns].mean())
# Select numeric columns for correlation analysis
numeric_data = data.select_dtypes(include=[np.number])
# Feature scaling
scaler = StandardScaler()
scaled_data = scaler.fit_transform(numeric_data)
scaled_data = pd.DataFrame(scaled_data, columns=numeric_columns)
# Split data into training and testing sets
train_size = int(len(data) * 0.8)
train_data = scaled_data[:train_size]
test_data = scaled_data[train_size:]
train_labels = data['Close_TAIEX'][:train_size]
test_labels = data['Close_TAIEX'][train_size:]
# Use Random Forest for feature selection
rf_selector = RandomForestRegressor(n_estimators=10)
rf_selector.fit(train_data, train_labels)
# Get feature importances and select top 10 features
feature_importances = pd.Series(rf_selector.feature_importances_, index=train_data.columns)
selected_features = feature_importances.nlargest(10).index
# Ensure 'Adj_Close' is included in the selected features
if 'Adj_Close' not in selected_features:
selected_features = selected_features.tolist()
selected_features.append('Adj_Close')
selected_features = pd.Index(selected_features)
# Use only selected features
train_data = train_data[selected_features]
test_data = test_data[selected_features]
# Generate future dates for prediction
future_dates = pd.date_range(start=data['Date'].iloc[-1], periods=91, inclusive='right')
# Generate future feature data (using the mean of the last available data as a placeholder)
future_features = np.tile(test_data.iloc[-1], (90, 1))
future_features = pd.DataFrame(future_features, columns=selected_features)
# Ensure future features have the same columns as original data
complete_future_features = pd.DataFrame(np.tile(scaled_data[selected_features].iloc[-1], (90, 1)), columns=selected_features)
# Train KNN model
knn_model = KNeighborsRegressor(n_neighbors=5)
knn_model.fit(train_data, train_labels)
knn_predictions = knn_model.predict(test_data)
knn_future_predictions = knn_model.predict(complete_future_features)
# Calculate and print MSE and MAE for KNN model
knn_mse = mean_squared_error(test_labels, knn_predictions)
knn_mae = mean_absolute_error(test_labels, knn_predictions)
print(f"KNN MSE: {knn_mse}")
print(f"KNN MAE: {knn_mae}")
# Print selected features
print("Selected features:", selected_features)
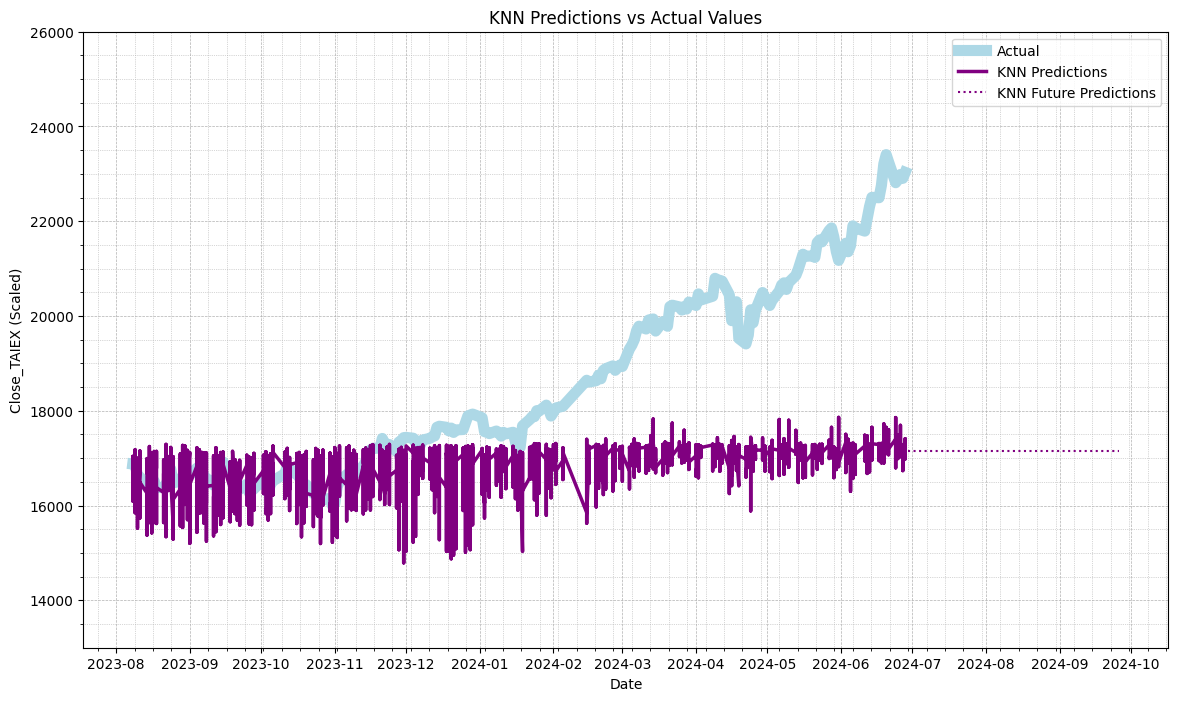
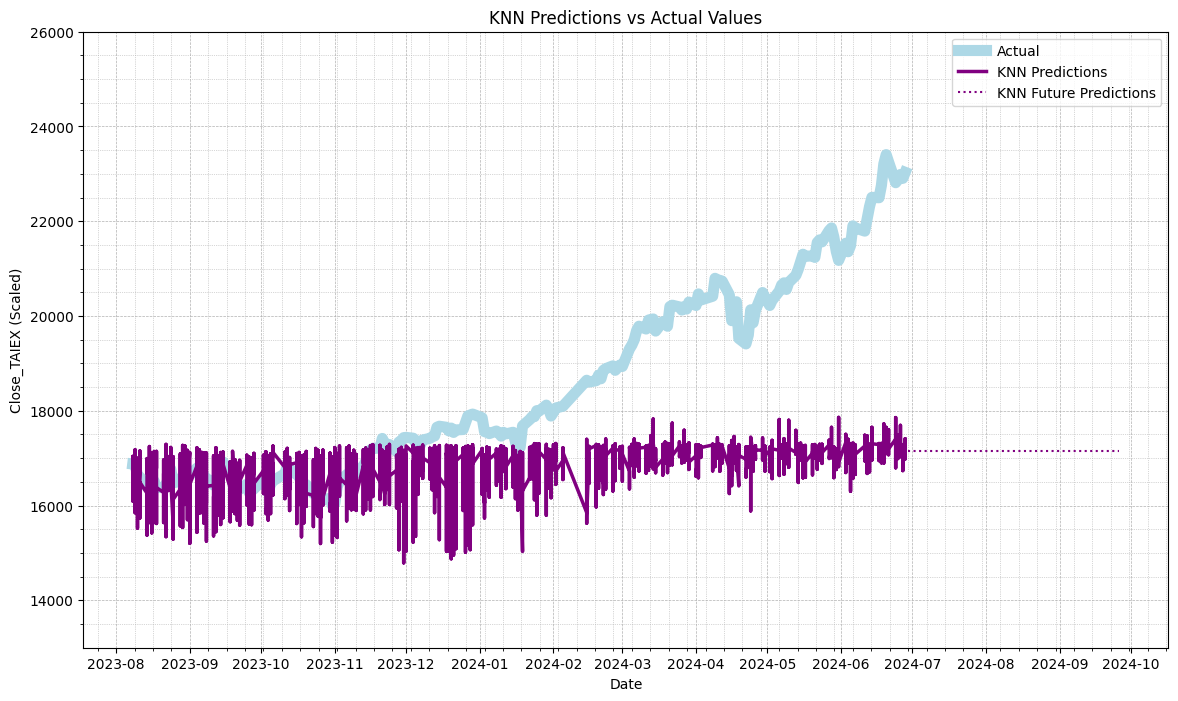
# Plot actual values vs KNN predictions
plt.figure(figsize=(14, 8))
# Plot actual values
plt.plot(data['Date'][train_size:], test_labels, label='Actual', color='lightblue', linewidth=8)
# Plot KNN predictions
plt.plot(data['Date'][train_size:], knn_predictions, label='KNN Predictions', color='purple', linewidth=2.5)
plt.plot(future_dates, knn_future_predictions, label='KNN Future Predictions', color='purple', linestyle='dotted')
plt.title('KNN Predictions vs Actual Values')
plt.xlabel('Date')
plt.ylabel('Close_TAIEX (Scaled)')
plt.legend()
# Set date format and annotate the first day of each month
plt.gca().xaxis.set_major_locator(mdates.MonthLocator())
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
# Set Y-axis limits
plt.ylim(13000, 26000)
# Add grid
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.minorticks_on()
plt.grid(True, which='minor', linestyle=':', linewidth=0.5)
# Show plot
plt.show()