TSMC price predict 0110

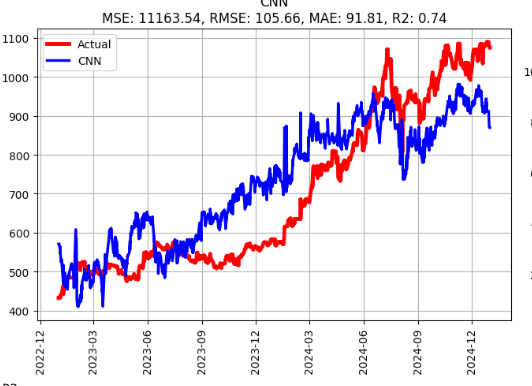
應該是特徵工程尚未找到訣竅
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.decomposition import PCA
from sklearn.linear_model import LinearRegression
from xgboost import XGBRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from statsmodels.tsa.arima.model import ARIMA
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Conv1D, MaxPooling1D, Flatten, Dropout
import tensorflow as tf
import matplotlib.dates as mdates
from google.colab import drive
# 挂載 Google Drive
drive.mount('/content/drive', force_remount=True)
save_path = '/content/drive/My Drive/tku_tsmc/ml_result_0110'
# 定義解釋變數與目標變數
TARGET_VARIABLE = 'Adj Close_2330.TW'
EXPLANATORY_VARIABLES = [
'High_^SOX','Adj Close_^SOX',
'CPI', 'ONRRP', 'DNSI',
'Adj Close_HG=F', 'High_HG=F', 'GEPU_PPP',
'Volume_^SOX', 'US10Y',
'Volume_2330.TW', 'SOX_RSI', 'TSMC_RSI', 'SOX_MACD'
]
# 第一步:載入數據
file_path = '/content/drive/My Drive/tku_tsmc/tsmc_processed_dataset_with_bollinger_updated.csv'
data = pd.read_csv(file_path)
data['Date'] = pd.to_datetime(data['Date'])
data = data.sort_values(by='Date')
# 第二步:篩選數據時間範圍
start_date = '2022-01-01'
end_date = '2025-01-01'
data = data[(data['Date'] >= start_date) & (data['Date'] <= end_date)]
# 檢查篩選後的數據量
print(f"篩選後的數據行數: {len(data)}")
if data.empty:
raise ValueError("篩選後的數據為空,請檢查時間範圍和數據源是否正確!")
# 第三步:根據時間切分數據
train_end_date = '2022-12-31'
test_start_date = '2023-01-01'
train_data = data[data['Date'] <= train_end_date]
test_data = data[data['Date'] >= test_start_date]
if train_data.empty or test_data.empty:
raise ValueError("訓練集或測試集為空,請檢查時間範圍是否正確!")
X_train = train_data[EXPLANATORY_VARIABLES]
y_train = train_data[TARGET_VARIABLE]
X_test = test_data[EXPLANATORY_VARIABLES]
y_test = test_data[TARGET_VARIABLE]
test_dates = test_data['Date']
# 檢查切分結果
print(f"訓練集大小: {len(X_train)}, 測試集大小: {len(X_test)}")
# 數據標準化(使用均值為 0,方差為 1 的標準化)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 定義模型
models = {
'Random Forest': RandomForestRegressor(n_estimators=100, max_depth=5),
'KNN': KNeighborsRegressor(n_neighbors=5),
'SVR': SVR(kernel='linear'),
'PCA + Linear Regression': 'PCA_LR',
'XGBoost': XGBRegressor(n_estimators=50, max_depth=5),
'ARIMA': 'ARIMA',
'LSTM': 'LSTM',
'CNN': 'CNN',
'Transformer': 'Transformer'
}
# 輔助函數
def calculate_metrics(y_true, y_pred):
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_true, y_pred)
r2 = r2_score(y_true, y_pred)
return mse, rmse, mae, r2
# 訓練與評估模型
predictions = {}
metrics = {}
for model_name, model in models.items():
if model_name == 'PCA + Linear Regression':
# PCA + Linear Regression 特殊處理
pca = PCA(n_components=3)
X_train_pca = pca.fit_transform(X_train_scaled)
X_test_pca = pca.transform(X_test_scaled)
lr = LinearRegression()
lr.fit(X_train_pca, y_train)
y_pred = lr.predict(X_test_pca)
elif model_name == 'ARIMA':
# ARIMA 特殊處理
arima_model = ARIMA(y_train, order=(5, 1, 0)).fit()
y_pred = arima_model.forecast(steps=len(y_test))
elif model_name == 'LSTM':
# LSTM 模型特殊處理
X_train_lstm = X_train_scaled.reshape((X_train_scaled.shape[0], 1, X_train_scaled.shape[1]))
X_test_lstm = X_test_scaled.reshape((X_test_scaled.shape[0], 1, X_test_scaled.shape[1]))
lstm_model = Sequential([
LSTM(50, activation='relu', input_shape=(X_train_lstm.shape[1], X_train_lstm.shape[2])),
Dense(1)
])
lstm_model.compile(optimizer='adam', loss='mse')
lstm_model.fit(X_train_lstm, y_train, epochs=10, batch_size=32, verbose=0)
y_pred = lstm_model.predict(X_test_lstm).flatten()
elif model_name == 'CNN':
# CNN 模型特殊處理
X_train_cnn = X_train_scaled.reshape((X_train_scaled.shape[0], X_train_scaled.shape[1], 1))
X_test_cnn = X_test_scaled.reshape((X_test_scaled.shape[0], X_test_scaled.shape[1], 1))
cnn_model = Sequential([
Conv1D(filters=64, kernel_size=2, activation='relu', input_shape=(X_train_cnn.shape[1], 1)),
MaxPooling1D(pool_size=2),
Flatten(),
Dense(50, activation='relu'),
Dense(1)
])
cnn_model.compile(optimizer='adam', loss='mse')
cnn_model.fit(X_train_cnn, y_train, epochs=10, batch_size=32, verbose=0)
y_pred = cnn_model.predict(X_test_cnn).flatten()
elif model_name == 'Transformer':
# Transformer 模型模擬處理
input_dim = X_train_scaled.shape[1]
transformer_model = Sequential([
Dense(64, activation='relu', input_dim=input_dim),
Dropout(0.1),
Dense(32, activation='relu'),
Dense(1)
])
transformer_model.compile(optimizer='adam', loss='mse')
transformer_model.fit(X_train_scaled, y_train, epochs=10, batch_size=32, verbose=0)
y_pred = transformer_model.predict(X_test_scaled).flatten()
else:
# 通用模型處理
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
predictions[model_name] = pd.Series(y_pred, index=test_dates)
mse, rmse, mae, r2 = calculate_metrics(y_test, y_pred)
metrics[model_name] = {'MSE': mse, 'RMSE': rmse, 'MAE': mae, 'R2': r2}
# 繪圖
fig, axs = plt.subplots(3, 3, figsize=(20, 15))
model_names = list(models.keys())
for i, model_name in enumerate(model_names):
row, col = divmod(i, 3)
ax = axs[row, col]
y_pred = predictions[model_name]
ax.plot(test_dates, y_test, label='Actual', linewidth=3.5, color='red')
ax.plot(test_dates, y_pred, label=f'{model_name}', linewidth=2.5, color='blue')
mse, rmse, mae, r2 = metrics[model_name].values()
ax.set_title(f"{model_name}\nMSE: {mse:.2f}, RMSE: {rmse:.2f}, MAE: {mae:.2f}, R2: {r2:.2f}")
ax.legend()
ax.grid()
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=3))
plt.setp(ax.xaxis.get_majorticklabels(), rotation=90)
plt.tight_layout()
plt.savefig(f'{save_path}/model_predictions.png')
plt.show()
# 輸出評估指標
metrics_df = pd.DataFrame(metrics).T
metrics_df.to_csv(f"{save_path}/model_metrics.csv")
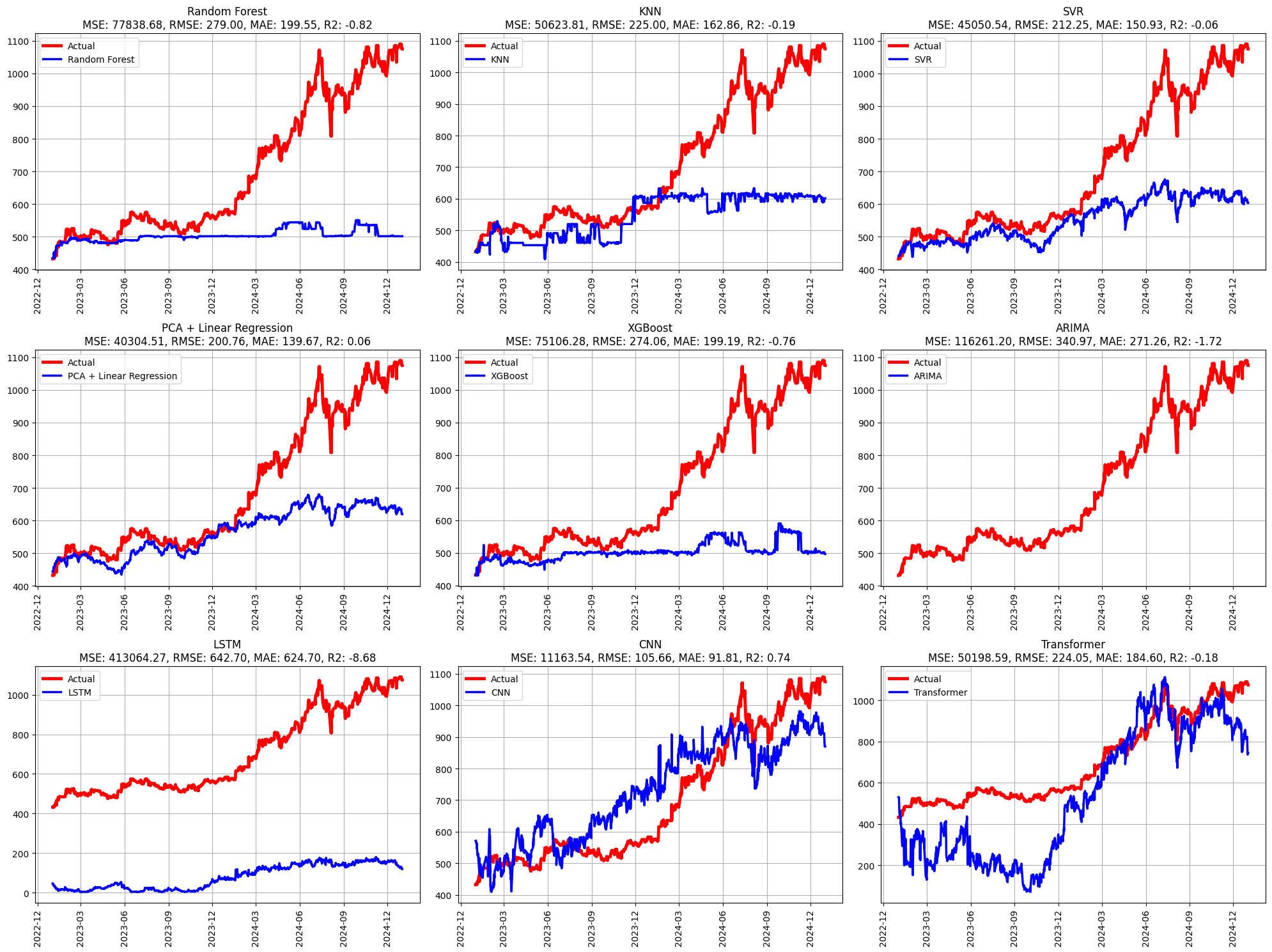
print(metrics_df) MSE RMSE MAE R2
Random Forest 77368.525591 278.151983 198.878378 -0.812707
KNN 50623.807601 224.997350 162.857740 -0.186091
SVR 45050.537357 212.251119 150.932680 -0.055512
PCA + Linear Regression 40304.514167 200.759842 139.666136 0.055685
XGBoost 75106.279252 274.055249 199.189258 -0.759704
ARIMA 116261.203429 340.970972 271.256574 -1.723943
LSTM 451441.300468 671.893816 649.427481 -9.577050
CNN 13107.866878 114.489593 97.160948 0.692889
Transformer 49670.415611 222.868606 179.180178 -0.163754