讀取數據
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
df = pd.read_csv('/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_0923.csv')
檢視資料結構
print(df.info())
print(df.head()) # 顯示前幾行數據

檢查缺失值
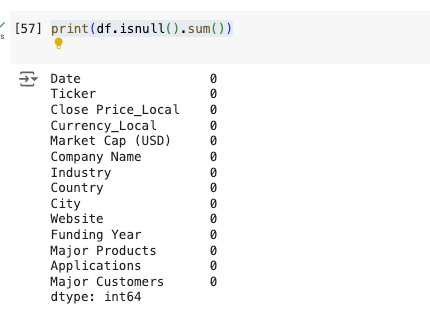
print(df.isnull().sum())
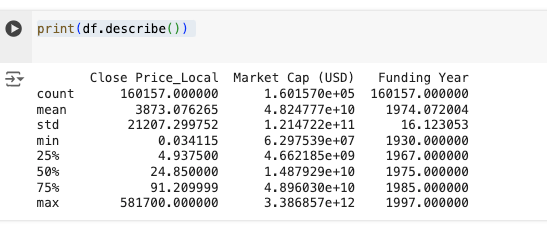
基本敘述統計
print(df.describe())
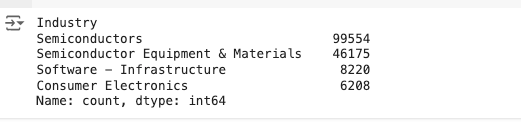
類別變數的分佈
print(df['Industry'].value_counts())
數據的分佈和統計圖形
import matplotlib.pyplot as plt
import pandas as pd
# 假設 df 已包含日期資料
# 轉換日期欄位為 datetime 格式
df['Date'] = pd.to_datetime(df['Date'])
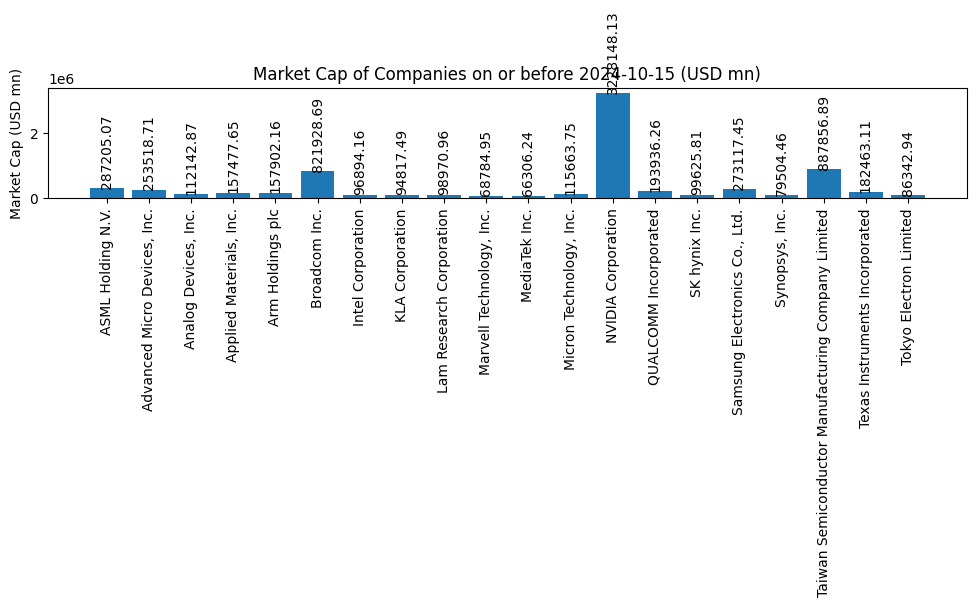
# 選擇 2024-10-15 或最近一天的數據
target_date = pd.Timestamp('2024-10-15')
# 找出 <= 2024-10-15 的最近一日數據
df_filtered = df[df['Date'] <= target_date].sort_values(by='Date', ascending=False).groupby('Company Name').first().reset_index()
# 將 Market Cap 的單位轉換為百萬
df_filtered['Market Cap (USD mn)'] = df_filtered['Market Cap (USD)'] / 1e6
# 繪製長條圖
plt.figure(figsize=(10, 6))
bars = plt.bar(df_filtered['Company Name'], df_filtered['Market Cap (USD mn)'])
# 設定 X 軸標籤並旋轉 90 度
plt.xticks(rotation=90)
# 添加 Market Cap 數值在每個長條的上方,並旋轉 90 度
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval, f'{yval:.2f}',
ha='center', va='bottom', rotation=90)
# 設定 Y 軸標籤
plt.ylabel('Market Cap (USD mn)')
# 設定標題
plt.title('Market Cap of Companies on or before 2024-10-15 (USD mn)')
# 顯示圖形
plt.tight_layout()
plt.show()
圖形修正
import matplotlib.pyplot as plt
import pandas as pd
# 假設 df 已包含日期資料
df['Date'] = pd.to_datetime(df['Date'])
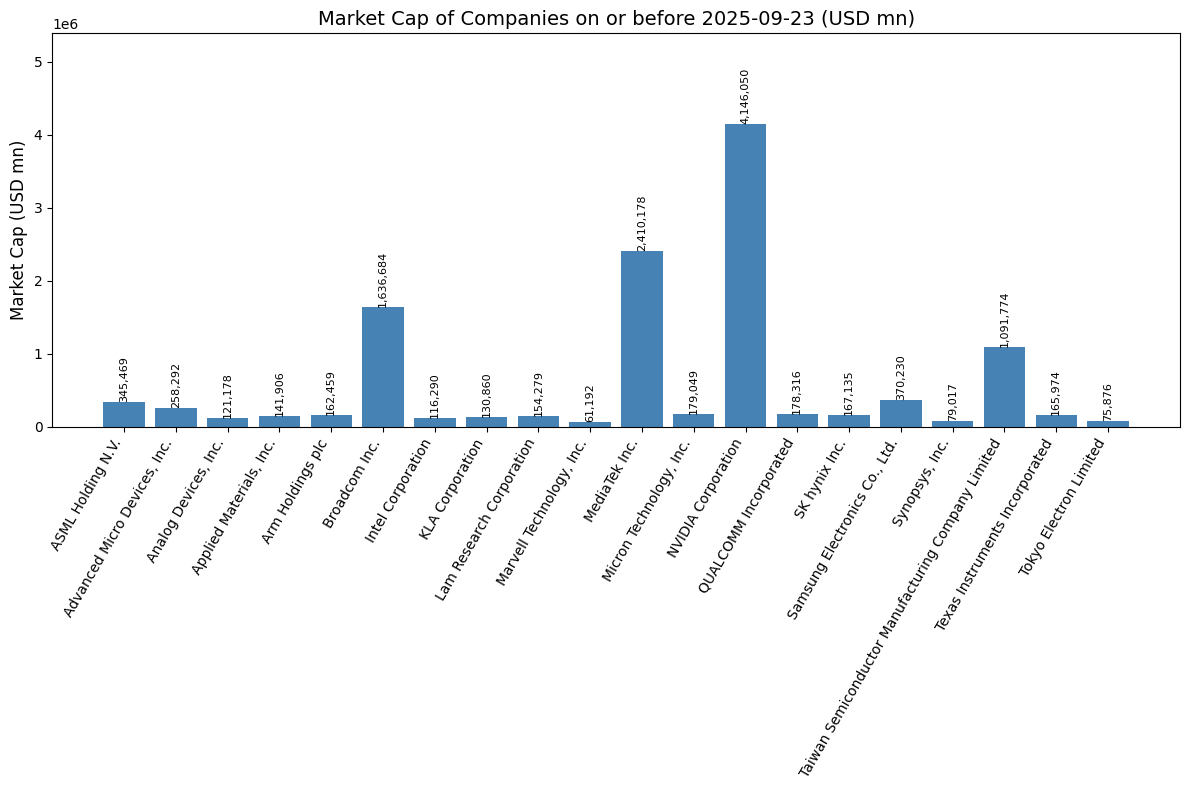
# 選擇 2025-09-17 或最近一天的數據
target_date = pd.Timestamp('2025-09-17')
# 找出 <= target_date 的最近一日數據
df_filtered = (
df[df['Date'] <= target_date]
.sort_values(by='Date', ascending=False)
.groupby('Company Name')
.first()
.reset_index()
)
# 將 Market Cap 的單位轉換為百萬
df_filtered['Market Cap (USD mn)'] = df_filtered['Market Cap (USD)'] / 1e6
# 設定圖表大小(高度拉高)
plt.figure(figsize=(12, 8))
bars = plt.bar(df_filtered['Company Name'], df_filtered['Market Cap (USD mn)'], color='steelblue')
# 設定 X 軸標籤並旋轉 60 度,避免擠在一起
plt.xticks(rotation=60, ha='right', fontsize=10)
# 設定 Y 軸上限,多留 30% 空間
ymax = df_filtered['Market Cap (USD mn)'].max()
plt.ylim(0, ymax * 1.3)
# 添加數值標籤在每個長條上方,文字旋轉 90 度
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval,
f'{yval:,.0f}',
ha='center', va='bottom',
rotation=90, fontsize=8)
# 設定標籤與標題
plt.ylabel('Market Cap (USD mn)', fontsize=12)
plt.title('Market Cap of Companies on or before 2025-09-23 (USD mn)', fontsize=14)
plt.tight_layout()
plt.show()
公司代碼簡寫修正
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import pandas as pd
# 假設 df 已包含日期資料
# 轉換日期欄位為 datetime 格式
df['Date'] = pd.to_datetime(df['Date'])
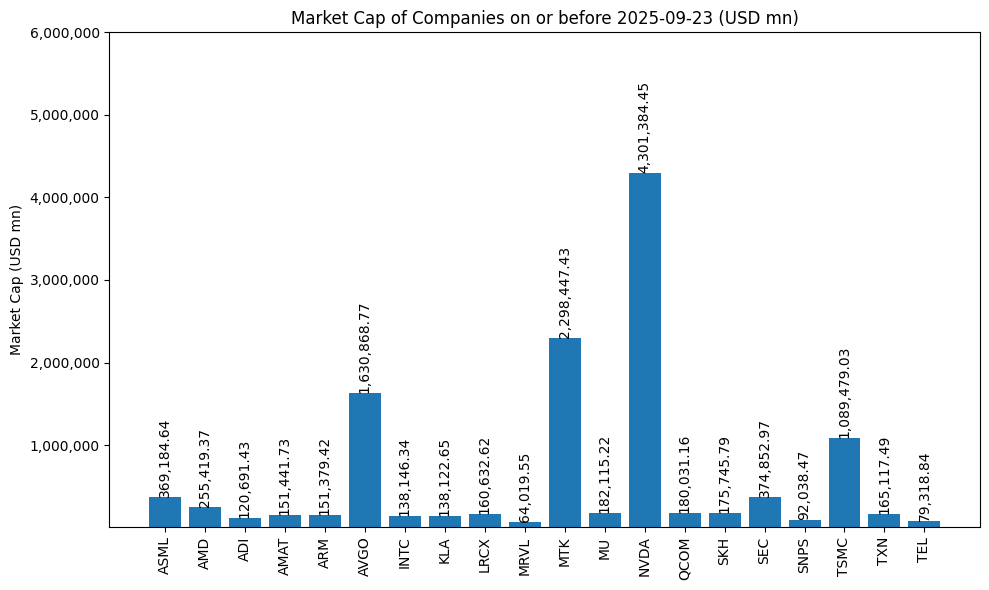
# 選擇 2025-09-23 或最近一天的數據
target_date = pd.Timestamp('2025-09-23')
# 找出 <= 2025-09-23 的最近一日數據
df_filtered = df[df['Date'] <= target_date].sort_values(by='Date', ascending=False).groupby('Company Name').first().reset_index()
# 將 Market Cap 的單位轉換為百萬
df_filtered['Market Cap (USD mn)'] = df_filtered['Market Cap (USD)'] / 1e6
# 使用公司簡稱作為 X 軸標籤 (可手動定義簡稱)
company_abbr = {
'ASML Holding N.V.': 'ASML',
'Advanced Micro Devices, Inc.': 'AMD',
'Analog Devices, Inc.': 'ADI',
'Applied Materials, Inc.': 'AMAT',
'Arm Holdings plc': 'ARM',
'Broadcom Inc.': 'AVGO',
'Intel Corporation': 'INTC',
'KLA Corporation': 'KLA',
'Lam Research Corporation': 'LRCX',
'Marvell Technology, Inc.': 'MRVL',
'MediaTek Inc.': 'MTK',
'Micron Technology, Inc.': 'MU',
'NVIDIA Corporation': 'NVDA',
'QUALCOMM Incorporated': 'QCOM',
'SK hynix Inc.': 'SKH',
'Samsung Electronics Co., Ltd.': 'SEC',
'Synopsys, Inc.': 'SNPS',
'Taiwan Semiconductor Manufacturing Company Limited': 'TSMC',
'Texas Instruments Incorporated': 'TXN',
'Tokyo Electron Limited': 'TEL'
}
df_filtered['Company Abbr'] = df_filtered['Company Name'].map(company_abbr)
# 繪製長條圖
plt.figure(figsize=(10, 6))
bars = plt.bar(df_filtered['Company Abbr'], df_filtered['Market Cap (USD mn)'])
# 設定 X 軸標籤並旋轉 90 度
plt.xticks(rotation=90)
# 設定 Y 軸範圍和千分號格式
plt.ylim(10000, 6000000)
plt.gca().yaxis.set_major_formatter(ticker.FuncFormatter(lambda x, _: f'{int(x):,}'))
# 添加 Market Cap 數值在每個長條的上方,並旋轉 90 度
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval, f'{yval:,.2f}',
ha='center', va='bottom', rotation=90)
# 設定 Y 軸標籤
plt.ylabel('Market Cap (USD mn)')
# 設定標題
plt.title('Market Cap of Companies on or before 2024-10-15 (USD mn)')
# 顯示圖形
plt.tight_layout()
plt.show()
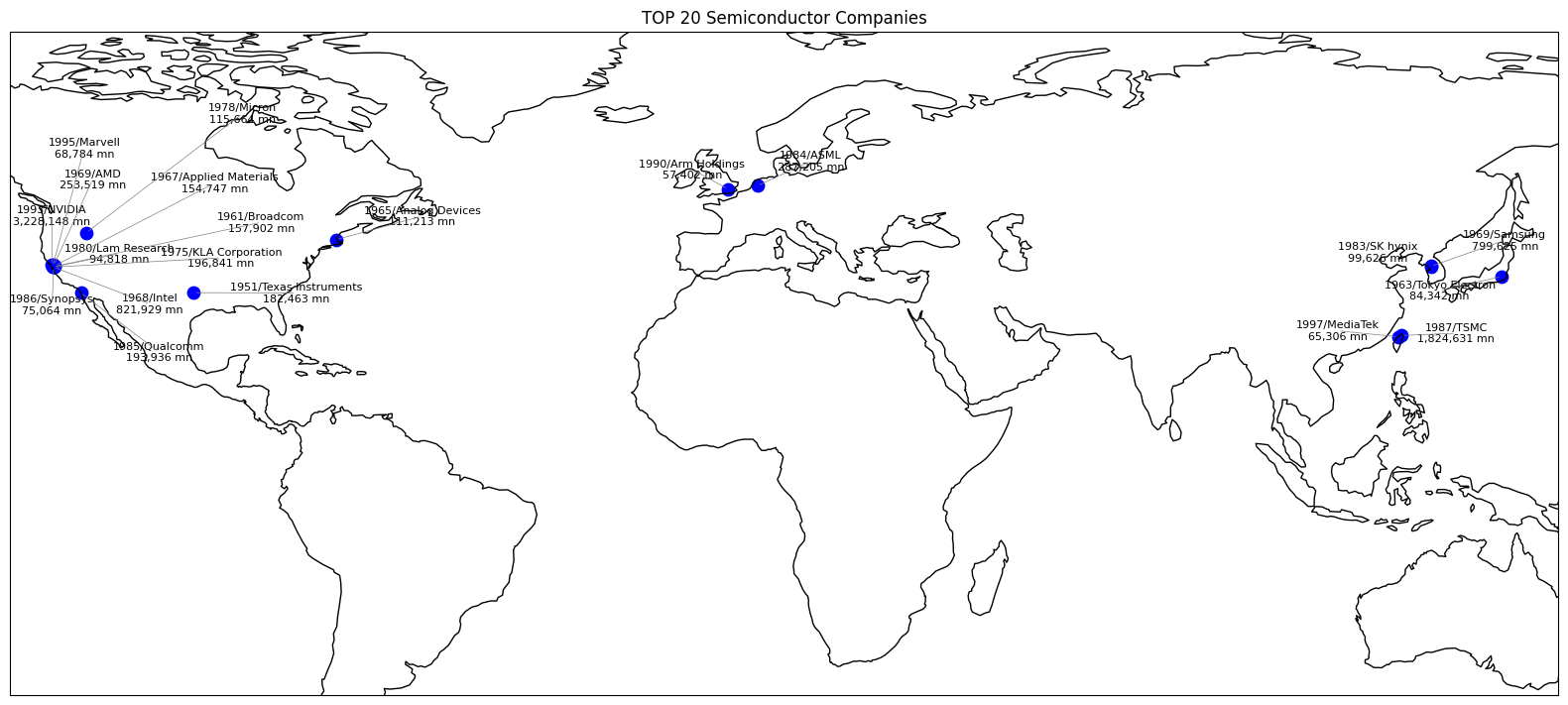
安裝 Cartopy ( 英國氣象局地圖包 )
pip install cartopy
畫一張地圖
import cartopy.crs as ccrs
import matplotlib.pyplot as plt
import pandas as pd
# 20 家公司總部位置資料
data = {
'Company Name': ['NVIDIA', 'ASML', 'TSMC', 'Samsung', 'Intel', 'Qualcomm', 'Broadcom',
'Micron', 'Texas Instruments', 'SK hynix', 'MediaTek', 'Applied Materials',
'AMD', 'KLA Corporation', 'Lam Research', 'Analog Devices', 'Arm Holdings',
'Synopsys', 'Tokyo Electron', 'Marvell'],
'Latitude': [37.7749, 52.0907, 25.0330, 37.5665, 37.3875, 32.7157, 37.4848,
43.6150, 32.7775, 37.4563, 24.7945, 37.6624, 37.7510, 37.4102,
37.4674, 42.3601, 51.5074, 37.3859, 35.6895, 37.5337],
'Longitude': [-122.4194, 5.1214, 121.5654, 126.9780, -122.0575, -117.1611, -122.1483,
-116.2023, -96.7970, 127.0419, 120.9615, -121.8747, -122.0312, -122.0595,
-121.9630, -71.0589, -0.1276, -122.0867, 139.6917, -122.2712],
'Funding Year': [1993, 1984, 1987, 1969, 1968, 1985, 1961,
1978, 1951, 1983, 1997, 1967, 1969, 1975,
1980, 1965, 1990, 1986, 1963, 1995],
'Market Cap (USD mn)': [3228148, 287205, 1824631, 799625, 821929, 193936, 157902,
115664, 182463, 99626, 65306, 154747, 253519, 196841,
94818, 111213, 57402, 75064, 84342, 68784]
}
# 創建DataFrame
df = pd.DataFrame(data)
# 創建地圖,設定 16:9 比例 (16 x 9 英吋)
fig, ax = plt.subplots(figsize=(16, 9), subplot_kw={'projection': ccrs.PlateCarree()})
ax.coastlines() # 繪製海岸線
# 設置地圖的視野範圍 (經度從 -130 到 150,緯度從 20 到 60)
ax.set_extent([-130, 150, -40, 80], crs=ccrs.PlateCarree())
# 標註公司位置,根據不同區域調整偏移
for idx, row in df.iterrows():
x_offset = 2 if row['Longitude'] < 0 else -2 # 西半球向右偏移,東半球向左偏移
y_offset = 0.5 if row['Latitude'] > 35 else -0.5 # 北緯度地區向上偏移,南緯度向下
ax.scatter(row['Longitude'], row['Latitude'], color='blue', s=100, transform=ccrs.PlateCarree()) # 標註地點
ax.text(row['Longitude'] + x_offset, row['Latitude'] + y_offset,
f"{row['Funding Year']}/{row['Company Name']}\n{row['Market Cap (USD mn)']:,} mn",
fontsize=8, ha='right', va='bottom', transform=ccrs.PlateCarree())
# 設定標題並顯示圖形
plt.title('TOP 20 Semiconductor Companies')
plt.tight_layout()
# 顯示圖形
plt.show()
新增一個欄位_Colse_Change %
import pandas as pd
# 讀取文件
input_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_0923.csv'
output_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_09231.csv'
# 讀取 CSV 文件
df = pd.read_csv(input_file)
# 計算每日的收盤價變動百分比(使用 Close_Price_Local)
df['Close_Price_Change%'] = df.groupby('Company Name')['Close Price_Local'].pct_change() * 100
# 保存結果為新的 CSV 文件
df.to_csv(output_file, index=False)
print(f"新文件已保存為: {output_file}")
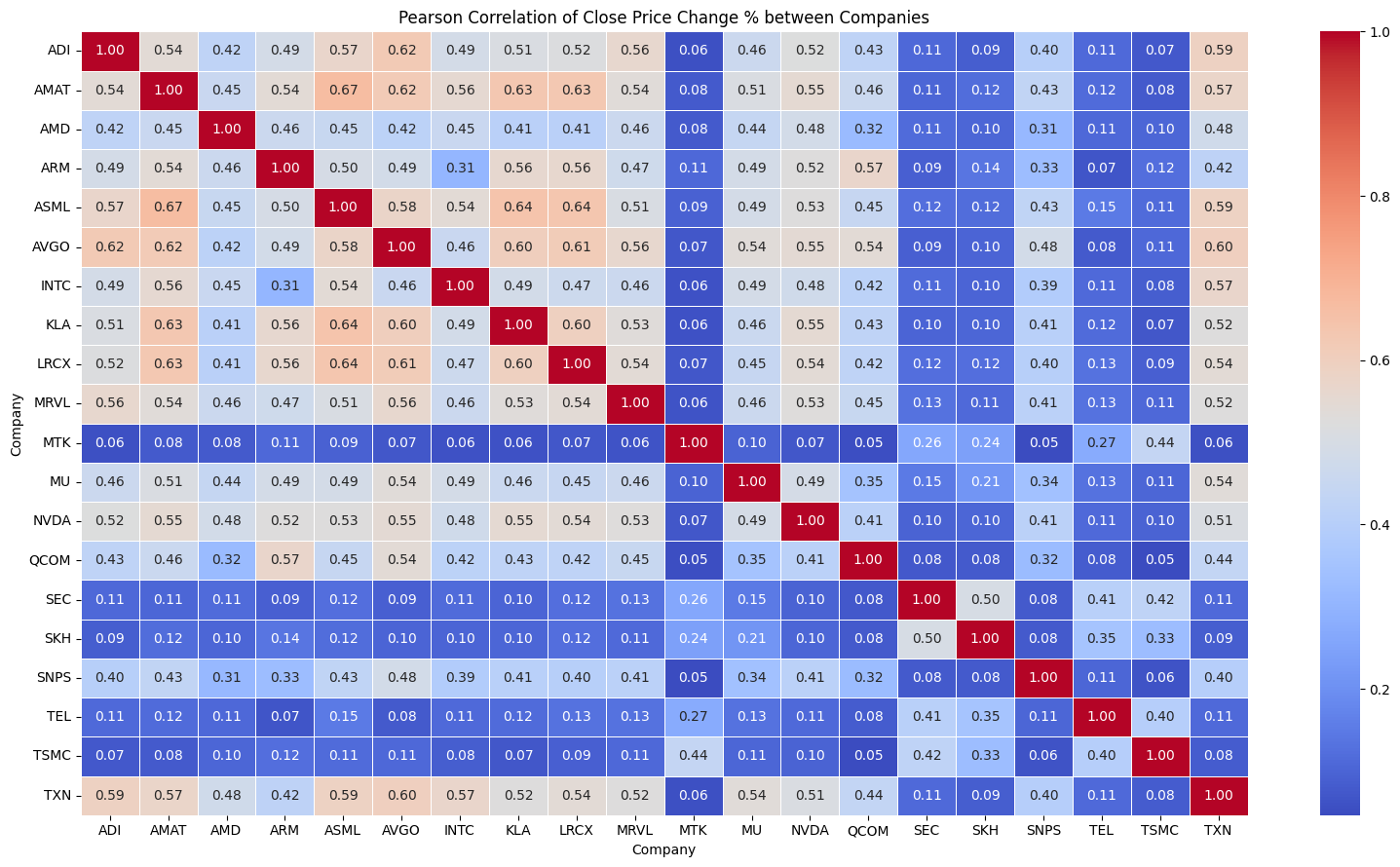
相關性分析
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import pearsonr
# 定義公司簡稱
company_abbr = {
'ASML Holding N.V.': 'ASML',
'Advanced Micro Devices, Inc.': 'AMD',
'Analog Devices, Inc.': 'ADI',
'Applied Materials, Inc.': 'AMAT',
'Arm Holdings plc': 'ARM',
'Broadcom Inc.': 'AVGO',
'Intel Corporation': 'INTC',
'KLA Corporation': 'KLA',
'Lam Research Corporation': 'LRCX',
'Marvell Technology, Inc.': 'MRVL',
'MediaTek Inc.': 'MTK',
'Micron Technology, Inc.': 'MU',
'NVIDIA Corporation': 'NVDA',
'QUALCOMM Incorporated': 'QCOM',
'SK hynix Inc.': 'SKH',
'Samsung Electronics Co., Ltd.': 'SEC',
'Synopsys, Inc.': 'SNPS',
'Taiwan Semiconductor Manufacturing Company Limited': 'TSMC',
'Texas Instruments Incorporated': 'TXN',
'Tokyo Electron Limited': 'TEL'
}
# 讀取文件
input_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_09231.csv'
df = pd.read_csv(input_file)
# 使用簡稱替換公司名稱
df['Company'] = df['Company Name'].replace(company_abbr)
# 計算每日的收盤價變動百分比(使用 Close_Price_Local)
df['Close_Price_Change%'] = df.groupby('Company Name')['Close Price_Local'].pct_change() * 100
# 透過 pivot_table 生成檢定所需的格式
pivot_data = df.pivot_table(index='Date', columns='Company', values='Close_Price_Change%')
# 計算 Pearson 檢定的相關性矩陣
correlation_matrix = pivot_data.corr(method='pearson')
# 打印相關性矩陣
print(correlation_matrix)
# 繪製相關性矩陣的熱力圖
plt.figure(figsize=(16, 9))
sns.heatmap(correlation_matrix, cmap='coolwarm', annot=True, fmt='.2f', linewidths=0.5)
# 設置標題和標籤
plt.title('Pearson Correlation of Close Price Change % between Companies')
plt.xlabel('Company')
plt.ylabel('Company')
# 顯示圖形
plt.tight_layout()
plt.show()
Company ADI AMAT AMD ARM ASML AVGO INTC \
Company
ADI 1.000000 0.541918 0.423366 0.486624 0.568896 0.621776 0.487018
AMAT 0.541918 1.000000 0.454196 0.544436 0.666901 0.619881 0.555079
AMD 0.423366 0.454196 1.000000 0.463046 0.451012 0.415794 0.453819
ARM 0.486624 0.544436 0.463046 1.000000 0.495585 0.485536 0.305722
ASML 0.568896 0.666901 0.451012 0.495585 1.000000 0.578797 0.544514
AVGO 0.621776 0.619881 0.415794 0.485536 0.578797 1.000000 0.455889
INTC 0.487018 0.555079 0.453819 0.305722 0.544514 0.455889 1.000000
KLA 0.510681 0.632632 0.410530 0.558197 0.643390 0.603210 0.485578
LRCX 0.516641 0.630973 0.408571 0.562002 0.635982 0.613218 0.465112
MRVL 0.561540 0.535809 0.461225 0.474167 0.508250 0.561123 0.461089
MTK 0.057143 0.077351 0.078549 0.108997 0.091158 0.071464 0.058916
MU 0.460685 0.511019 0.443854 0.487499 0.488852 0.536306 0.488299
NVDA 0.522410 0.552755 0.482511 0.524515 0.526296 0.547520 0.478040
QCOM 0.425003 0.458807 0.319627 0.569955 0.446204 0.544711 0.417745
SEC 0.109014 0.105563 0.114888 0.089351 0.120939 0.087458 0.113838
SKH 0.085792 0.119534 0.104326 0.135799 0.119577 0.100415 0.099826
SNPS 0.401077 0.430971 0.312300 0.326379 0.426871 0.484249 0.386781
TEL 0.110707 0.116325 0.107175 0.066312 0.149715 0.078622 0.113225
TSMC 0.072692 0.077878 0.103152 0.122251 0.114173 0.106240 0.083760
TXN 0.590414 0.574693 0.477645 0.420051 0.589021 0.597949 0.569759
Company KLA LRCX MRVL MTK MU NVDA QCOM \
Company
ADI 0.510681 0.516641 0.561540 0.057143 0.460685 0.522410 0.425003
AMAT 0.632632 0.630973 0.535809 0.077351 0.511019 0.552755 0.458807
AMD 0.410530 0.408571 0.461225 0.078549 0.443854 0.482511 0.319627
ARM 0.558197 0.562002 0.474167 0.108997 0.487499 0.524515 0.569955
ASML 0.643390 0.635982 0.508250 0.091158 0.488852 0.526296 0.446204
AVGO 0.603210 0.613218 0.561123 0.071464 0.536306 0.547520 0.544711
INTC 0.485578 0.465112 0.461089 0.058916 0.488299 0.478040 0.417745
KLA 1.000000 0.597073 0.532974 0.059414 0.456168 0.550244 0.426259
LRCX 0.597073 1.000000 0.542129 0.072306 0.447227 0.544406 0.423479
MRVL 0.532974 0.542129 1.000000 0.062846 0.462426 0.527370 0.451346
MTK 0.059414 0.072306 0.062846 1.000000 0.098443 0.070321 0.051490
MU 0.456168 0.447227 0.462426 0.098443 1.000000 0.491772 0.350716
NVDA 0.550244 0.544406 0.527370 0.070321 0.491772 1.000000 0.414545
QCOM 0.426259 0.423479 0.451346 0.051490 0.350716 0.414545 1.000000
SEC 0.099445 0.121546 0.130619 0.260848 0.149158 0.095688 0.075216
SKH 0.104053 0.122636 0.109864 0.242886 0.213560 0.102754 0.076789
SNPS 0.405212 0.403582 0.412785 0.046350 0.343524 0.414020 0.323829
TEL 0.115637 0.131608 0.131444 0.271901 0.128999 0.110760 0.080498
TSMC 0.070768 0.090978 0.105954 0.440420 0.105783 0.096346 0.046957
TXN 0.524982 0.542830 0.524364 0.055881 0.537954 0.510233 0.435174
Company SEC SKH SNPS TEL TSMC TXN
Company
ADI 0.109014 0.085792 0.401077 0.110707 0.072692 0.590414
AMAT 0.105563 0.119534 0.430971 0.116325 0.077878 0.574693
AMD 0.114888 0.104326 0.312300 0.107175 0.103152 0.477645
ARM 0.089351 0.135799 0.326379 0.066312 0.122251 0.420051
ASML 0.120939 0.119577 0.426871 0.149715 0.114173 0.589021
AVGO 0.087458 0.100415 0.484249 0.078622 0.106240 0.597949
INTC 0.113838 0.099826 0.386781 0.113225 0.083760 0.569759
KLA 0.099445 0.104053 0.405212 0.115637 0.070768 0.524982
LRCX 0.121546 0.122636 0.403582 0.131608 0.090978 0.542830
MRVL 0.130619 0.109864 0.412785 0.131444 0.105954 0.524364
MTK 0.260848 0.242886 0.046350 0.271901 0.440420 0.055881
MU 0.149158 0.213560 0.343524 0.128999 0.105783 0.537954
NVDA 0.095688 0.102754 0.414020 0.110760 0.096346 0.510233
QCOM 0.075216 0.076789 0.323829 0.080498 0.046957 0.435174
SEC 1.000000 0.499564 0.076720 0.407232 0.423196 0.112434
SKH 0.499564 1.000000 0.079850 0.352210 0.326435 0.086746
SNPS 0.076720 0.079850 1.000000 0.105648 0.061736 0.397336
TEL 0.407232 0.352210 0.105648 1.000000 0.396922 0.111470
TSMC 0.423196 0.326435 0.061736 0.396922 1.000000 0.082757
TXN 0.112434 0.086746 0.397336 0.111470 0.082757 1.000000
Pearson 檢定
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import pearsonr
# 定義公司簡稱
company_abbr = {
'ASML Holding N.V.': 'ASML',
'Advanced Micro Devices, Inc.': 'AMD',
'Analog Devices, Inc.': 'ADI',
'Applied Materials, Inc.': 'AMAT',
'Arm Holdings plc': 'ARM',
'Broadcom Inc.': 'AVGO',
'Intel Corporation': 'INTC',
'KLA Corporation': 'KLA',
'Lam Research Corporation': 'LRCX',
'Marvell Technology, Inc.': 'MRVL',
'MediaTek Inc.': 'MTK',
'Micron Technology, Inc.': 'MU',
'NVIDIA Corporation': 'NVDA',
'QUALCOMM Incorporated': 'QCOM',
'SK hynix Inc.': 'SKH',
'Samsung Electronics Co., Ltd.': 'SEC',
'Synopsys, Inc.': 'SNPS',
'Taiwan Semiconductor Manufacturing Company Limited': 'TSMC',
'Texas Instruments Incorporated': 'TXN',
'Tokyo Electron Limited': 'TEL'
}
# 讀取文件
input_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_09231.csv'
df = pd.read_csv(input_file)
# 使用簡稱替換公司名稱
df['Company'] = df['Company Name'].replace(company_abbr)
# 計算每日的收盤價變動百分比(使用 Close_Price_Local)
df['Close_Price_Change%'] = df.groupby('Company Name')['Close Price_Local'].pct_change() * 100
# 透過 pivot_table 生成檢定所需的格式
pivot_data = df.pivot_table(index='Date', columns='Company', values='Close_Price_Change%')
# 創建一個空的 DataFrame 來存放結果
results = pd.DataFrame(columns=['Company 1', 'Company 2', 'Pearson R', 'P-value'])
# 計算每兩家公司之間的 Pearson R 和 P 值
companies = pivot_data.columns
for i in range(len(companies)):
for j in range(i+1, len(companies)): # 避免重複計算相同的組合
comp1 = companies[i]
comp2 = companies[j]
# 去除 NaN 值,避免影響計算
valid_data = pivot_data[[comp1, comp2]].dropna()
if not valid_data.empty:
# 計算 Pearson 相關性和 P 值
r_value, p_value = pearsonr(valid_data[comp1], valid_data[comp2])
# 將結果存入 DataFrame
new_row = pd.DataFrame({
'Company 1': [comp1],
'Company 2': [comp2],
'Pearson R': [r_value],
'P-value': [p_value]
})
results = pd.concat([results, new_row], ignore_index=True)
# 顯示結果
print(results)
# 保存為 CSV 文件,如果需要保存結果到文件
output_file = '/content/drive/My Drive/Semicon_Analysis/pearson_correlation_results.csv'
results.to_csv(output_file, index=False)
results = pd.concat([results, new_row], ignore_index=True)
Company 1 Company 2 Pearson R P-value
0 ADI AMAT 0.541918 0.000000e+00
1 ADI AMD 0.423366 0.000000e+00
2 ADI ARM 0.486624 2.209092e-31
3 ADI ASML 0.568896 0.000000e+00
4 ADI AVGO 0.621776 0.000000e+00
.. ... ... ... ...
185 SNPS TSMC 0.061736 1.185282e-06
186 SNPS TXN 0.397336 1.231097e-317
187 TEL TSMC 0.396922 4.839307e-231
188 TEL TXN 0.111470 1.351283e-18
189 TSMC TXN 0.082757 7.163894e-11
[190 rows x 4 columns]
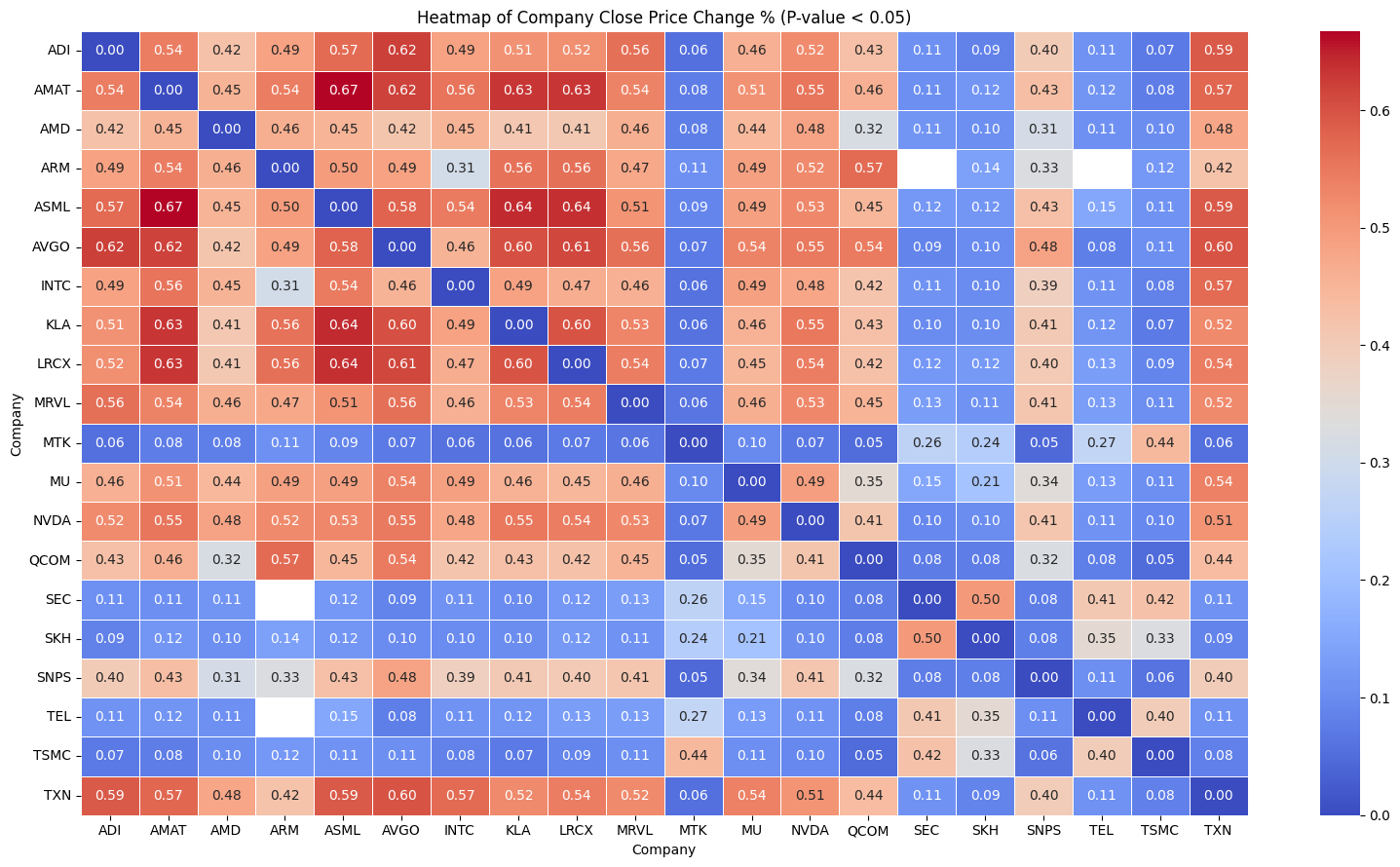
重新提供 Heatmap of Price Change% , 基於 P-value <0.05
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import pearsonr
import numpy as np
# 定義公司簡稱
company_abbr = {
'ASML Holding N.V.': 'ASML',
'Advanced Micro Devices, Inc.': 'AMD',
'Analog Devices, Inc.': 'ADI',
'Applied Materials, Inc.': 'AMAT',
'Arm Holdings plc': 'ARM',
'Broadcom Inc.': 'AVGO',
'Intel Corporation': 'INTC',
'KLA Corporation': 'KLA',
'Lam Research Corporation': 'LRCX',
'Marvell Technology, Inc.': 'MRVL',
'MediaTek Inc.': 'MTK',
'Micron Technology, Inc.': 'MU',
'NVIDIA Corporation': 'NVDA',
'QUALCOMM Incorporated': 'QCOM',
'SK hynix Inc.': 'SKH',
'Samsung Electronics Co., Ltd.': 'SEC',
'Synopsys, Inc.': 'SNPS',
'Taiwan Semiconductor Manufacturing Company Limited': 'TSMC',
'Texas Instruments Incorporated': 'TXN',
'Tokyo Electron Limited': 'TEL'
}
# 讀取文件
input_file = '/content/drive/My Drive/Semicon_Analysis/semiconductor_merged_09231.csv'
df = pd.read_csv(input_file)
# 使用簡稱替換公司名稱
df['Company'] = df['Company Name'].replace(company_abbr)
# 計算每日的收盤價變動百分比(使用 Close_Price_Local)
df['Close_Price_Change%'] = df.groupby('Company Name')['Close Price_Local'].pct_change() * 100
# 透過 pivot_table 生成檢定所需的格式
pivot_data = df.pivot_table(index='Date', columns='Company', values='Close_Price_Change%')
# 創建一個空的 DataFrame 來存放結果
correlation_matrix = pd.DataFrame(np.zeros((len(pivot_data.columns), len(pivot_data.columns))),
columns=pivot_data.columns, index=pivot_data.columns)
# 計算每兩家公司之間的 Pearson R 和 P 值
for i in range(len(pivot_data.columns)):
for j in range(i+1, len(pivot_data.columns)): # 避免重複計算相同的組合
comp1 = pivot_data.columns[i]
comp2 = pivot_data.columns[j]
# 去除 NaN 值,避免影響計算
valid_data = pivot_data[[comp1, comp2]].dropna()
if not valid_data.empty:
# 計算 Pearson 相關性和 P 值
r_value, p_value = pearsonr(valid_data[comp1], valid_data[comp2])
# 只在 p-value < 0.05 的情況下填入 Pearson R 值,否則設為 NaN
if p_value < 0.05:
correlation_matrix.loc[comp1, comp2] = r_value
correlation_matrix.loc[comp2, comp1] = r_value
else:
correlation_matrix.loc[comp1, comp2] = np.nan
correlation_matrix.loc[comp2, comp1] = np.nan
# 繪製相關性矩陣的熱力圖,只顯示符合條件的公司 P Value < 0.05
plt.figure(figsize=(16, 9))
sns.heatmap(correlation_matrix, cmap='coolwarm', annot=True, fmt='.2f', linewidths=0.5, mask=correlation_matrix.isnull())
# 設置標題和標籤
plt.title('Heatmap of Company Close Price Change % (P-value < 0.05)')
plt.xlabel('Company')
plt.ylabel('Company')
# 顯示圖形
plt.tight_layout()
plt.show()